Minerva System
![]()
- Autor: Lucas S. Vieira (lucasvieira@protonmail.com)
- Repositório: https://github.com/luksamuk/minerva-system
- Uso: Não-comercial/didático
- Licença: GPLv3
Este documento trata da documentação em geral do Minerva System. O sistema é majoritariamente programado utilizando o método eXtreme Programming, portanto esta documentação não é exaustiva no sentido de uma especificação completa, posto que os requisitos do sistema estarão em constante mudança.
A modificação deste documento é enormemente encorajada, mas é mais importante a prototipação constante do sistema que a escrita da especificação propriamente dita.
Para mitigar os problemas que podem ocorrer mediante foco diminuído neste documento, recomenda-se um grande uso de testes unitários e também de documentação ad-hoc no código dos módulos do projeto, de preferência envolvendo as ferramentas padrão das linguagens aqui utilizadas.
O Minerva System NÃO POSSUI NENHUM INTUITO COMERCIAL, SENDO VEDADA SUA COMERCIALIZAÇÃO. Além disso, não há nenhuma garantia com relação à utilização desse sistema. Em outras palavras, não é garantido que ele funcione como esperado em produção.
TODO E QUALQUER RECURSO NESSE SISTEMA DEVE SER VISTO COMO MATERIAL DIDÁTICO, PRODUZIDO COM O MERO INTUITO DE APRENDIZAGEM A RESPEITO DE DEVOPS, MICROSSERVIÇOS, ENGENHARIA E ARQUITETURA DE SOFTWARE.
O código do sistema é aberto e distribuído sob uma licença de Software Livre,
mais especificamente a GNU General Public License, versão 3 (GPLv3). Para
detalhes sobre a licença, consulte o arquivo LICENSE no repositório
Changelog
Todas as mudanças notáveis neste projeto serão documentadas nesse arquivo.
O formato é baseado em Keep a Changelog, e este projeto adere ao Versionamento Semântico.
Não-lançado
Relação de versões de microsserviços:
REST- v0.3.2RUNONCE- v0.3.0USER- v0.3.1SESSION- v0.1.3DISPATCH- v0.1.1- Front-End - v0.1.1 (pré-alfa)
Adicionado
- Geração de imagens: Reabilitado target de compilação para ARM64.
- Geração de imagens: Adicionado script que gera uma working tree limpa ao gerar recipe do Cargo Chef.
RUNONCE: Estruturas para preparação de message broker (virtual hosts e filas fixas).DISPATCH: Criação do microsserviço.- Devcontainers do VSCode: Adicionada configuração inicial (ainda instável).
- Kubernetes: Exposição dos serviços e ferramentas
REST, Grafana e PgAdmin4 nas rotas/api,/grafanae/pgadmin, respectivamente, através do uso de Ingresses. - Kubernetes: Adicionados serviços Prometheus e Grafana, com alguns dashboards padronizados.
- Minerva9: Adicionada documentação para o MVC e repositório do projeto.
- Kubernetes: Adição de configurações para deploy em ambientes IoT.
DATA: Adicionado DTO fixo para retorno de dados de sessão durante login.- REST: API agora possui documentação e ferramentas para teste através de Swagger
e RapiDoc (respectivamente através das rotas
/swaggere/rapidoc). - Sonar: Adicionados arquivos de configuração do SonarQube para deploy em Kubernetes.
- Testes: Adicionada configuração (projeto e pipeline de testes) para deploy dos dados de testes e coberturas para o Sonar, via Tailscale.
- Testes: Adicionada documentação individual sobre testes, principalmente testes de carga.
- Sonar: Adicionada documentação sobre Quality Gates do projeto.
Modificado
- Rust: Define versão 1.65.0 para todo o projeto.
RUNONCE: Spinlocks de aguardo de disponibilidade de serviços agora realizam sleep assíncrono de dois segundos após cada falha.RUNONCE: Spinlocks de disponibilidade agora também operam de forma assíncrona.- Kubernetes: Ajustes nos Ingresses existentes para que funcionem adequadamente, através de Traefik.
- Kubernetes: Ajustes nas configurações de deploy para que haja menos arquivos.
- Kubernetes: Ajustes nos limites de réplicas e de recursos requisitados para alguns serviços.
- MongoDB: Downgrade para versão 4.
- Tonic atualizado para v0.8.2.
- Prost atualizado para v0.11.
- CI/CD: Adicionada dependência do compilador de Protocol Buffers (
protoc), no build via Docker e no ambiente de testes do GitHub Actions. - Compose/Swarm: Exposição das portas do PostgreSQL e do MongoDB para acesso remoto.
- Compose/Swarm: Removidas as ferramentas Mongo Express, Redis Commander e pgAdmin4, já que essas configurações são pensadas primariamente como debug. Para monitorar e inspecionar o MongoDB, o Redis e o PostgreSQL, veja ferramentas ad-hoc como MongoDB Compass, RESP.app ou DBeaver, respectivamente.
- PostgreSQL: Atualizado para versão 15.
- Documentação: Adicionados diagramas separados para cada deployment no Kubernetes, bem como um diagrama geral da arquitetura do mesmo.
REST: Requisições agora exigem token através de Bearer Token.REST: Requisições agora demandam tenant no início das rotas.REST: Todas as rotas agora possuem tipos de resposta bem-definidos, possibilitando extração de schema para OpenAPI.REST: Alteradas as variáveis de ambiente designando profile e nível de log do Rocket nos vários tipos de deploy (local, Compose, Swarm, K8s)
Consertado
USER: Ao remover um usuário, envia mensagem requisitando remoção das sessões do mesmo (cache e coleção de sessões).USER: Caso um usuário falhe em ser criado (ao final da inserção), será considerado como se já existisse.REST(K8s): ConfigMap próprio estava sendo ignorado e agora é utilizado.REST: A API agora é capaz de lidar com a exposição de suas próprias rotas sob um endpoint específico (como/api, por exemplo; isso também funciona para a especificação OpenAPI e para Swagger e Rapidoc).
Removido
- Removidos projetos Rust de módulos ainda não-iniciados, que causavam lentidão desnecessária na compilação.
REST: Removidos exemplos de requisições na documentação das rotas (prefira a documentação via Postman ou use Swagger ou RapiDoc).REST: Removidas cores no texto do console durante deploy em k8s.
Segurança
- Chaves dos dados de sessão armazenados no Redis agora são codificados usando Base64 para reduzir legibilidade.
Problemas conhecidos
- A ferramenta Redis Commander conhecidamente funciona apenas em arquitetura AMD64, o que inviabiliza seu deploy no Kubernetes em ambientes ARM. Isso significa que clusters com o Minerva que sejam totalmente configurados em arquitetura ARM perderão alguma observabilidade quanto ao Redis. Adicionalmente, essa limitação também foi refletida na configuração da ferramenta via k8s.
- As configurações atuais para os Ingresses estão muito relacionadas ao que é necessário para realizar deploy em K3s, com Traefik sendo utilizado como backend para Ingresses. Isso inviabiliza um pouco o uso de Minikube e Microk8s.
- Builds de imagens Docker com Rust quebram o Qemu com uso excessivo de memória,
caso a variável de ambiente
CARGO_NET_GIT_FETCH_WITH_CLInão esteja definida comotrue.
v2 - 2022-07-05
Relação de versões de microsserviços:
USER- v0.2.2SESSION- v0.1.2RUNONCE- v0.2.1REST- v0.2.2- Front-End - v0.1.1 (pré-alfa)
Adicionado
SESSION: Alteração do serviço para abrigar uso de cache via Redis;REST: Catchers para tipos de retorno comuns e retorno genérico padrão;- Documentação: Adição de diagramas iniciais de caso de uso e sequência;
- Projeto: Adição de CHANGELOG e regras de versionamento semântico.
Modificado
USER: Alteração do nome do serviço deUSERSparaUSER, evitando maiores enganos;- Geração de Imagens: Dockerfile para gerar imagens agora foi unificado, incluindo compilação do frontend também no script, e agora utiliza BuildKit por padrão;
- Geração de Imagens: Imagens Docker agora são geradas usando Alpine Linux como base, reduzindo tamanho e footprint em deploys no Compose/Swarm/K8s.
Consertado
REST: Erros na conexão com um microsserviço agora retornam um erro 503 (Recurso Indisponível);- Documentação: Problema na exportação de diagramas usando PlantUML no Github Pages.
Removido
- Documentação: Removido o Dockerfile específico para PgAdmin4. A partir de agora, será usada a imagem oficial do PgAdmin4, e o arquivo de configuração será montado como necessário (via arquivos de configuração do Docker Compose e do Docker Stack, ou via ConfigMap no K8s).
Segurança
- Geral: Removida a dependência da crate
rustc-serializena configuração da cratechrono(em confirmidade com alerta Dependabot), para todos os módulos.
Problemas conhecidos
- Geração de Imagens: O target para ARM64 na criação das imagens Docker foi desabilitado até que seja corrigido um bug no BuildKit que faz com que o Qemu consuma RAM arbitrariamente ao realizar compilação via emulação de hardware.
v1 - 2022-06-17
Relação de versões de microsserviços:
USERS- v0.2.1SESSION- v0.1.1RUNONCE- v0.2.0REST- v0.2.0- Front-End - v0.0.1 (pré-alfa)
Adicionado
- Criação de schemas do banco de dados relacional (PostgreSQL 14);
- Criação das coleções do banco de dados não-relacional (MongoDB 5);
- Adição de protocol buffers;
- Adição do microsserviço gRPC
USERS; - Adição do microsserviço gRPC
SESSION; - Adição da base para alguns outros microsserviços;
- Adição da documentação básica;
- Adição das bibliotecas
DATAeRPC; - Adição do microsserviço gRPC
REST(Rocket v0.5.0-rc.2); - Adição de rotas de autenticação e CRUD de usuários;
- Adição de pooling de conexões com o banco de dados não-relacional;
- Adição de logs para operações de CRUD de usuários e de sessão;
- Adição de configuração de teste para Docker Compose;
- Adição de configuração de deploy para Docker Swarm;
- Adição de configuração de deploy para Kubernetes;
- Adição de conceito básico de Front-End (com Flutter 3.0);
- Adição de automatização de testes;
- Adição de geração de documentação (mdBook,
cargo doc,flutter doc) via GitHub Pages.
Estrutura geral do projeto
O Minerva System é uma aplicação pensada com finalidade de estudo, mas que não deixa de ser um sistema real e com um público alvo. Sendo assim, trata-se de um sistema gerencial, sem finalidade comercial.
O projeto envolve um licenciamento de Software Livre, e busca implementar uma estrutura de microsserviços. Em outras palavras, o sistema opera através da modificação de uma única base de dados, mas possui módulos separados para modificação de partes específicas.
Minerva também utiliza uma dicotomia front-end/back-end, de forma que a aplicação constitui-se de uma interface gráfica web, acessível via navegador, e uma intraestrutura constituída de um ponto de entrada que se comunica com os serviços específicos que a interface gráfica requisitar.
Segmentos
Como supracitado, Minerva constitui-se de microsserviços, especialmente em seu back-end. Para tanto, deve-se pensar em três grandes segmentos:
- Front-End (aplicação web envolvendo interface gráfica);
- Back-End (aplicação com um gateway REST, constituída de microsserviços gRPC);
- Banco de Dados (relacional para gerenciamento de dados, não-relacional para gerenciamento de entidades temporárias, e sistemas de caching e mensageria).
Adicionalmente, existe uma maleabilidade que permite a confecção de outros tipos de Front-End que se comuniquem diretamente com o Back-End da aplicação, como por exemplo, através de programas nativos para Desktop e Mobile.
A imagem a seguir é uma supersimplificação da visão externa do sistema, sem sua complexidade intrínseca.
Front-End
O Minerva System possui vários front-ends para algumas plataformas, para Web, console e até mesmo para o sistema operacional Plan 9.
Os capítulos a seguir falarão de tais interfaces.
Interface para Plan 9 from Bell Labs

O Minerva System possui uma interface gráfica projetada especificamente para o sistema operacional Plan 9 from Bell Labs ou, mais especificamente, para um fork moderno e robusto desse sistema operacional, conhecido como 9front.
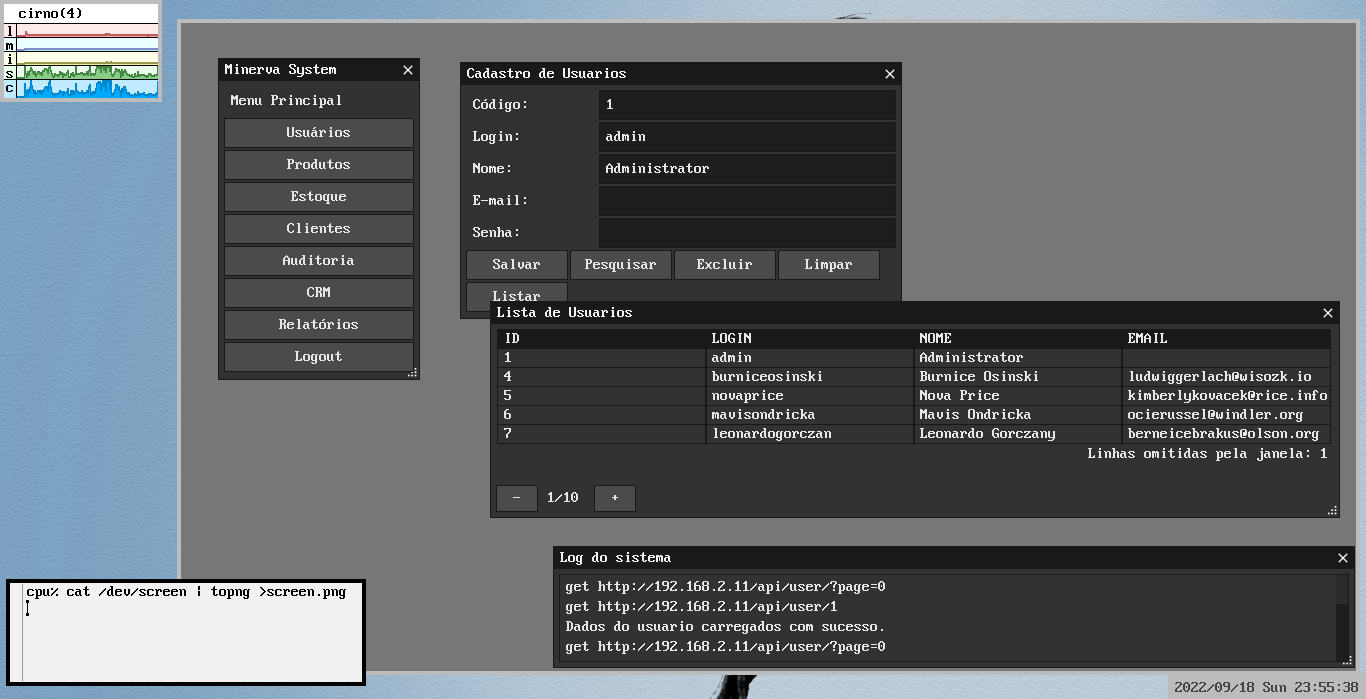
Apresentação
O front-end conhecido como Minerva9 é uma aplicação totalmente construída na linguagem C, mais especificamente no dialeto de C suportado no Plan 9 (parcialmente C99-compliant), que tenta levar em consideração as características desse sistema peculiar, especialmente no que tange à forma como o sistema lida com o protocolo HTTP.
Motivação
A existência dessa aplicação está relacionada principalmente ao fato de, sendo bem sincero, eu (Lucas) ser um entusiasta, utilizador e estudioso assíduo desse sistema e de suas tecnologias, que continuam atuais mesmo nos dias de hoje.
Este front-end possui algumas características especiais que evidenciam algumas funcionalidades do Plan 9, o que inclui:
- Uso extensivo da biblioteca
microui, uma biblioteca para construir aplicações gráficas no Plan 9, através da linguagem C; - Uso extensivo de
webfs(4), como forma de realizar requisições REST à API do Minerva, com autenticação baseada em bearer token. Isso está em conformidade com a ideia de utilizar arquivos e sistemas de arquivos como recursos, em vez de importar novas bibliotecas, quando estas não são realmente necessárias (ou existentes); - Desenvolvimento rápido de uma interface simples, similar à interface para terminal
minerva_tui(também discutida nessa documentação), que não pode ser compilada no Plan 9, ainda que o sistema suporte a linguagem Go; - Talvez uma prova-de-conceito para estudar a estrutura do sistema Plan 0, que possui algumas ideias interessantes, conceitos e utilitários que ainda podem ser utilizados em outros sistemas.
Documentação
Não.
Agradecimentos
Obrigado a sigrid por desenvolver a biblioteca microui de forma brilhante, e pelas
demais pessoas que mantém o 9front e provam que Plan 9 ainda é muito legal.
Licenciamento
O Minerva9 é distribuído sob uma licença GPLv3, que pode ser consultada em seu repositório.
Interface para Terminal
O Minerva System possui também uma interface feita para rodar em terminal. Essa interface foi planejada principalmente para testes com a API, não sendo necessariamente planejada para a usabilidade de usuários leigos no uso do console.
Exemplo
O vídeo abaixo mostra um exemplo do uso da interface CLI para gerenciar o cadastro de usuários.
Download
O código da interface CLI encontra-se no GitHub. É possível baixar binários pré-compilados para algumas arquiteturas e sistemas operacionais, mais especificamente Windows (x86_64) e Linux (x86_64 e ARM64).
Os binários podem ser baixados na página de Releases.
Back-End
O back-end Minerva compõe-se de microsserviços, com uma interface comum de comunicação externa que seja simples de usar para os padrões atuais.
O back-end compõe-se dos seguintes componentes:
- Componente de API: um serviço composto de rotas HTTP, sendo portanto uma API REST. Este serviço requisita dados sob demanda a cada serviço, dependendo do recurso que foi requisitado por via externa. É efetivamente o intermediário entre Minerva e o mundo externo. As requisições entre este serviço e os outros deverão ser feito através da abertura de uma requisição gRPC em que este módulo seja o cliente requisitante; as respostas recebidas via gRPC são então retornadas como resposta às requisições recebidas via REST, após tratamento para serialização como JSON.
- Componente de usuários: Servidor gRPC responsável por realizar o CRUD de usuários e por verificar as regras de negócio destas operações.
- Componente de sessão: Servidor gRPC responsável por realizar login, logoff, verificação de senha e gerenciamento de sessão de usuários.
- Componente de produtos: Servidor gRPC responsável por realizar o CRUD de produtos e por verificar as regras de negócio destas operações.
- Componente de estoque: Servidor gRPC responsável por realizar regras de negócios relacionadas a estoque de produtos (início, baixa, lançamento, etc).
- Componente de inquilinos: Servidor gRPC responsável por coordenar a criação ou remoção de novos inquilinos no sistema. Cada inquilino possuirá seu próprio conjunto de dados, e isso afetará diretamente na infraestrutura reservada para o mesmo (criação ou remoção de bancos de dados ou segmentos específicos em certos serviços).
- Componente de relatórios: Servidor gRPC responsável pela geração de relatórios humanamente legíveis, envolvendo portanto agregação de dados de acordo com o que for externamente requisitado.
- Componente de clientes: Servidor gRPC responsável por realizar o CRUD e a coordenação de dados de clientes do inquilino em questão.
- Componente de auditoria: Servidor gRPC responsável por gerenciar a consulta ao logs de auditoria do sistema.
- Componente de comunicação instantânea: Servidor gRPC para CRM através de comunicação via canais de mensagens instantâneas.
Os serviços gRPC supracitados tratam-se de servidores gRPC que podem receber conexões vindas do ponto de entrada REST ou mesmo entre si. Além disso, os serviços gRPC devem ser capazes de se comunicar com bancos de dados, que são recursos essenciais para os mesmos (exemplo: PostgreSQL, MongoDB, Redis). Estes serviços devem gravar log de suas operações, mais especificamente nas operações de inserção, atualização e exclusão.
A API REST sempre se comunica diretamente com os serviços gRPC, e os mesmos são encorajados a se comunicarem entre si quando for necessário estabelecer comunicação bloqueante entre os mesmos. Todavia, quando for necessário estabelecer comunicação não-bloqueante entre os microsserviços (leia-se, quando o retorno para os usuários for desnecessário), será feito o uso de mensageria com despacho automático, sem comunicação gRPC direta.
Bibliotecas
As bibliotecas planejadas para o sistema são:
-
minerva-rpc: Implementação de protocolos gRPC e de mensagens destes protocolo. Deve ser importado em todos os módulos, sendo essencial para a criação de clientes e servidores gRPC. Os modelos de comunicação implementados para si devem ser também convertidos para e a partir dos DTOs do módulo de dados. -
minerva-data: Implementação de utilitários de comunicação com banco de dados (PostgreSQL) e objetos de transferência de dados (DTOs). Deve ser importado em todos os módulos, exceto na comunicação REST. Os DTOs também devem implementar traits e utilitários para conversão das mensagens implementadas emminerva-rpcpara os DTOs desta biblioteca. -
minerva-cache: Implementação de utilitários de comunicação com cache e armazenamento temporário in-memory (Redis). Deve ser importado principalmente no módulo de sessão. -
minerva-broker: Implementação de utilitários de comunicação com message brokers (RabbitMQ). Deve ser importado em qualquer módulo que envolva processamento assíncrono, mas principalmente no módulo de despacho de mensagens.
Módulos
Os módulos planejados para o sistema são:
-
minerva-tenancy: Servidor gRPC para CRUD de inquilinos. Deve ser capaz de gerenciar inquilinos, mas um inquilino não pode ser deletado através desse serviço, apenas desativado. Apenas administradores do sistema podem ter acesso. -
minerva-user: Servidor gRPC para CRUD de usuários. Deve ser capaz de manipular as regras de negócios relacionadas a clientes. -
minerva-session: Servidor gRPC para gerência de sessão de usuário. -
minerva-product: Servidor gRPC para CRUD de produtos. Deve ser capaz de manipular as regras de negócios relacionadas a produtos, mas que não envolvam controle de estoque. -
minerva-stock: Servidor gRPC para CRUD de estoque de produtos. Deve ser capaz de manipular as regras de negócios relacionadas a estoque, mas que não envolvam manipulação de produtos. -
minerva-rest: Servidor REST para comunicação com os demais módulos executáveis. Possui rotas que apontam para serviços específicos, e é por definição um cliente gRPC de todos os servidores gRPC. -
minerva-runonce: Serviço avulso para configuração do ambiente, de forma assíncrona. Responsável pela execução de migrações do banco de dados e outras operações de configuração inicial. -
minerva-report: Servidor gRPC para geração de relatórios. Deve receber dados com formatação esperada de um relatório, e então deverá gerar um arquivo PDF e retorná-lo inteiramente como resposta. -
minerva-client: Servidor gRPC para CRUD de clientes. Deve ser capaz de manipular as regras de negócios relacionadas a clientes. -
minerva-audit: Servidor gRPC para gerenciamento de logs de auditoria. Possibilita a consulta aos logs de auditoria do sistema. -
minerva-comm: Servidor gRPC para comunicação externa com clientes via mensagens instantâneas. -
minerva-dispatch: Serviço de escuta de message broker e despacho de mensagens para demais serviços.
Portas
Os serviços, independente de serem gRPC ou REST, devem ser executados em certas portas padrão para evitarem conflitos durante o tempo de depuração. Cada porta deve também ser configurável através de variáveis de ambiente.
A tabela a seguir discrimina as variáveis de ambiente e as portas padrão de acordo com o serviço em questão.
| Serviço | Variável | Valor |
|---|---|---|
| REST | ROCKET_PORT | 9000 |
| USER | USER_SERVICE_PORT | 9010 |
| SESSION | SESSION_SERVICE_PORT | 9011 |
No caso do serviço REST, verifique o arquivo Rocket.toml para avaliar
a configuração em desenvolvimento e em produção do mesmo.
Gateways
Os serviços também podem operar em máquinas diferentes, dependendo de sua rota.
Normalmente, quando todos os serviços são executados manualmente na mesma
máquina, operamos com uma rota localhost. Nesse caso, a variável de
ambiente de cada serviço é definida como esse valor.
Todavia, num ambiente de orquestração de contêineres (como Docker Compose ou Kubernetes), cada serviço estará operando de forma separada, e poderá comunicar-se com os outros serviços por intermédio de uma rede interna ao qual apenas os serviços têm acesso de forma explícita. Assim, as variáveis de ambiente que determinam o nome do servidor devem ser definidas manualmente, de acordo com a forma como o deploy de cada serviço foi realizado.
A seguir, temos uma tabela relacionando os sistemas com sas variáveis de ambiente. Os valores das variáveis serão definidos de acordo com o orquestrador de contêineres sendo utilizado.
No caso do serviço REST, verifique o arquivo Rocket.toml para avaliar
a configuração em desenvolvimento e em produção do mesmo.
| Serviço | Variável de ambiente |
|---|---|
| Banco de dados SQL | DATABASE_SERVICE_SERVER |
| Banco de dados NoSQL | MONGO_SERVICE_SERVER |
| Cache Redis | REDIS_SERVICE_SERVER |
| Message Broker RabbitMQ | RABBITMQ_SERVICE_SERVER |
| ------------------------- | --------------------------- |
| REST | REST_SERVICE_SERVER |
| USER | USER_SERVICE_SERVER |
| SESSION | SESSION_SERVICE_SERVER |
Documentação do Software
Este capítulo lista links para a documentação das partes pertinentes ao código do Minerva System.
Por padrão, a documentação é escrita em Inglês, e pode ser muito pertinente durante a implementação de novas partes do sistema.
Não se esqueça de consultar estes documentos com frequência.
API
- Documentação da API
Documentação da API REST (Postman, em Inglês).
Serviços externos
Microsserviços
- RUNONCE
Utilitário de configuração inicial do sistema durante um deploy. - SESSION
Serviço de gerenciamento de sessão de usuário. - USER
Serviço de gerenciamento de usuários. - DISPATCH
Serviço de consumo de filas do RabbitMQ e despacho de operações. - PRODUCT (não implementado)
Serviço de gerenciamento de produtos. - REPORT (não implementado)
Serviço de gerenciamento e emissão de relatórios. - STOCK (não implementado)
Serviço de gerenciamento de estoques de produtos. - CLIENT (não implementado)
Serviço de gerenciamento de clientes. - AUDIT (não implementado)
Serviço de gerenciamento de logs de auditoria. - TENANCY (não implementado)
Serviço de gerenciamento de inquilinos. - COMM (não implementado)
Serviço de gerenciamento de comunicações via mensagem instantânea.
Bibliotecas
- DATA
Biblioteca de manipulação de DTOs e conversões de dados. - RPC
Biblioteca de implementação de Protocol Buffers, mensagens gRPC e afins. - CACHE
Biblioteca para uso e acesso ao cache via serviço Redis. - BROKER
Biblioteca para uso, acesso e configuração do serviço RabbitMQ e mensageria.
Especificação do Projeto
Os capítulos a seguir tratarão de documentação ligada à especificação funcional e arquitetural do projeto.
Multi-Tenancy
O Minerva System é um sistema multi-tenant. Isso significa que é capaz de gerenciar bancos de dados diferentes dependendo do tenant (cliente do serviço) atual. No Sistema Minerva, isso é gerenciado de acordo com a forma como as requisições são recebidas.
Atualmente, o multi-tenancy é gerenciado de forma estática, através
de um arquivo de configuração, mas em breve será gerenciado através
do microsserviço TENANCY.
Configuração
Os tenants devem ser gerenciados através do arquivo tenancy.toml.
A seguir, um exemplo do conteúdo em potencial deste arquivo.
[[tenants]]
name = "Minerva System"
database = "minerva"
connections = 5
[[tenants]]
name = "Test Database"
database = "teste"
connections = 5
[[tenants]]
name = "Comercial Fulano S/A"
database = "comercial-fulano"
connections = 5
Criação dos bancos de dados
O serviço RUNONCE deverá executar a criação dos bancos de dados, caso
não seja possível conectar-se aos mesmos. Isso deve ser feito sobretudo
através da leitura do arquivo tenancy.toml, encontrado na pasta de
execução do projeto.
Caso um novo tenant seja adicionado ao sistema, o serviço RUNONCE
deverá ser forçadamente executado para que o sistema fique apto a
utilizar o banco de dados para aquele tenant.
O sistema RUNONCE deverá, para cada tenant listado em tenancy.toml:
- Tentar conectar-se aos bancos em questão. Se isso não for possível, deverá criá-los;
- Executar as migrations (no BD relacional) para aquele tenant;
- Criar as coleções e índices (no BD não-relacional) para aquele tenant;
- Criar o usuário
admin(no BD relacional) para aquele tenant; - Criar as devidas filas de despacho de mensagens (no message broker) para aquele tenant.
Banco de Dados Relacional
As próximas seções dizem respeito a partes relacionadas à estrutura do banco de dados relacional (PostgreSQL) e a como modificá-la.
Executando migrations
As migrations são uma parte vital do Sistema Minerva, não apenas porque definem as tabelas do banco de um tenant, mas porque também definem os schemas para a programação dos módulos.
Pré-requisitos
- Rust (compilador
rustce gerenciador de pacotescargo, versão 1.60.0 ou superior); - Diesel (versão 1.4.1 ou superior, com suporte a PostgreSQL);
diesel_clicom suporte a PostgreSQL;- Docker versão 20.10 ou superior.
Para instalar o diesel_cli apenas com suporte a PostgreSQL, use o
seguinte comando:
cargo install diesel_cli --no-default-feature --features postgres
Considerações importantes
Toda e qualquer migration deve ser criada no diretório do módulo
minerva-runonce, especificamente porque este diretório possui também
as configurações de acesso e de geração de schema em
minerva-data/src/schema.rs.
Além disso, sempre execute todos os comandos abaixo no diretório do módulo
minerva-runonce.
Configuração inicial
Para começar, crie um contêiner Docker para cada um dos bancos de dados:
./make_postgres_db.sh
./make_mongo_db.sh
./make_redis_db.sh
Isso criará contêineres executando PostgreSQL 15, MongoDB 4 e Redis 7.
Após a criação dos contêineres, o processo de preparação dos bancos de dados pode ser um pouco demorado. Acompanhe este processo observando os logs:
# Banco relacional
docker logs -f minerva-postgres
# Banco não-relacional
docker logs -f minerva-mongo
# Cache
docker logs -f minerva-redis
Em seguida, execute a operação inicial de criação de um banco de dados.
Para tanto, vamos criar um banco chamado minerva e executar todas as
migrations nele, logo de cara:
diesel setup --database-url="postgres://postgres:postgres@localhost/minerva"
Criando uma migration
Para criar uma migration, use um comando similar ao seguinte:
diesel migration generate <nome_da_migration>
Substitua <nome_da_migration> por um nome que faça sentido.
Isso gerará uma nova migration no diretório migrations,
que possuirá os arquivos up.sql e down.sql. Edite-os de acordo
com o necessário.
Executando migrations
Para executar todas as migrations pendentes, execute o comando:
diesel migration run --database-url="postgres://postgres:postgres@localhost/minerva"
Isso também poderá reconstruir o arquivo minerva-data/src/schema.rs, a depender
de mudanças no schema.
Para testar a última migration executada:
diesel migration redo --database-url="postgres://postgres:postgres@localhost/minerva"
Removendo banco de dados de teste
Para remover os bancos de dados de teste criados no Docker, use os comandos a seguir.
Estes comandos servem para, respectivamente, parar a execução dos contêineres e então excluí-los.
docker stop minerva-postgres minerva-mongo minerva-redis
docker rm minerva-postgres minerva-mongo minerva-redis
Banco de Dados Não-Relacional
As próximas seções dizem respeito a partes relacionadas à estrutura do banco de dados não-relacional (MongoDB) e a seu uso.
Coleções
Assim como no caso do banco de dados relacional, o banco de dados não-relacional (criado através do MongoDB) também trabalha com um sistema multi-tenant, sendo portanto representável como um banco de dados para cada cliente.
Ainda assim, para cada cliente, algumas coleções são essenciais de serem criadas e configuradas até mesmo antes do primeiro acesso.
Coleção session
A coleção session armazena documentos contendo dados de sessão de um usuário.
A responsabilidade de armazenar dados dos usuários é do banco de dados relacional,
assim como a responsabilidade de autenticá-los é do serviço SESSION. Esta coleção,
todavia, armazena os dados de autenticação após a realização de um login válido.
Cada documento nesta coleção possui um tempo de expiração de uma semana, o que
alinha-se com o tempo máximo de uma sessão do usuário ser, igualmente, uma semana.
A gerência desse tempo de expiração se dá através de um campo creationDate no
documento, que armazena um timestamp indicando a data de início daquela sessão.
Caso o documento não possua esse campo, o MongoDB, por padrão, acaba não expirando-o.
A responsabilidade da definição e criação adequada do creationDate é do serviço
SESSION.
Cache
A ferramenta Redis é extensamente usada no Minerva System para armazenamento de informações em cache. Este capítulo descreve algumas das situações e entidades para as quais o cache é feito, e as regras de negócio envolvidas.
Lembre-se de que o Redis é utilizado em ambientes onde o acesso é feito por aplicações seguras, o que significa que, por design, o mesmo deverá ser capaz de armazenar informações sensíveis sem maiores problemas. Sendo um banco de dados in-memory, deve-se esperar que sua reinicialização apague seus dados.
Cache de sessão
Uma sessão do usuário é armazenada no banco de dados não-relacional (MongoDB)
na forma de um documento, na coleção session, com um prazo de expiração de
uma semana.
Esse processo é feito durante o processo de login. Todavia, para evitar maior
estresse no serviço SESSION e no banco de dados não-relacional, o documento
do MongoDB é serializado para JSON, e armazenado como valor no Redis, com um
tempo de vida de 24 horas. A chave dessa informação é gerada a partir das
informações do tenant e do ID do objeto no MongoDB.
Quando uma sessão for removida, além de realizar a remoção no MongoDB, o sistema também fica a cargo de remover a sessão no banco de dados também.
Mensageria
O Minerva System utiliza o RabbitMQ para operações de mensageria. Essas operações fazem-se necessárias sobretudo quando há necessidade de operações assíncronas, especialmente as que não dependem diretamente de interação do usuário no sistema, ou que são intensivas em termos de recursos.
Situações para uso de mensageria
O uso de mensageria deverá ser realizado em operações que devem ser gerenciadas a partir de eventos, sobretudo quando a operação é intensiva e com eventual chance de timeout. Esses casos incluem, mas não se limitam a:
- Processamento de dados em batch;
- Operações mais demoradas (ex. geração de relatório);
- Notificações do usuário (ex. conclusão de processos);
- Operações mais simples, mas que não deverão bloquear o uso do resto do sistema (ex. uma operação decorrente de outra).
Atuais usos no sistema
A seguir, serão listados os atuais usos de mensageria no Minerva System.
Remoção de sessões ao remover usuário
Ao remover o usuário, para garantir que o mesmo não possa realizar mais nenhuma operação no sistema, é interessante realizar a remoção de suas sessões. Isso é feito de forma desvinculada ao processo de remoção do usuário em si, seguindo o seguinte fluxo:
- O administrador requisita a remoção de um usuário para o tenant atual.
- O usuário é removido pelo serviço USER, para o tenant atual.
- O serviço USER enfileira, na fila específica do tenant para isso, uma requisição de remoção de todas as sessões do usuário recentemente removido.
- O serviço DISPATCH escuta as mensagens na fila do tenant em questão, recebendo a mensagem de remoção de sessões.
- O serviço DISPATCH requisita todas as sessões do usuário removido que estiverem na coleção de sessões do tenant atual, no MongoDB.
- O serviço DISPATCH requisita ao serviço SESSION que cada uma dessas sessões seja removida.
- Para cada sessão, SESSION remove a sessão do MongoDB para o tenant atual, e remove a sessão do cache no serviço Redis, caso exista.
- O serviço DISPATCH dá a mensagem como consumida e retorna à operação de escuta para a próxima mensagem.
Coleta de Logs
O Minerva System possui um sistema de coleta de logs especificamente no contexto de um deploy para Kubernetes.
A coleta é feita para cada nó do Kubernetes, através de um DaemonSet, que criará um pod em cada nó do cluster. Cada pod terá acesso de leitura aos logs de todos os pods em execução no nó; periodicamente, cada pod do Fluentd enviará um log stash para o serviço do Elasticsearch. O usuário poderá então consultar logs, realizar queries e montar dashboards através do Kibana.
O diagrama a seguir é uma representação simplificada de como a coleta de logs opera.
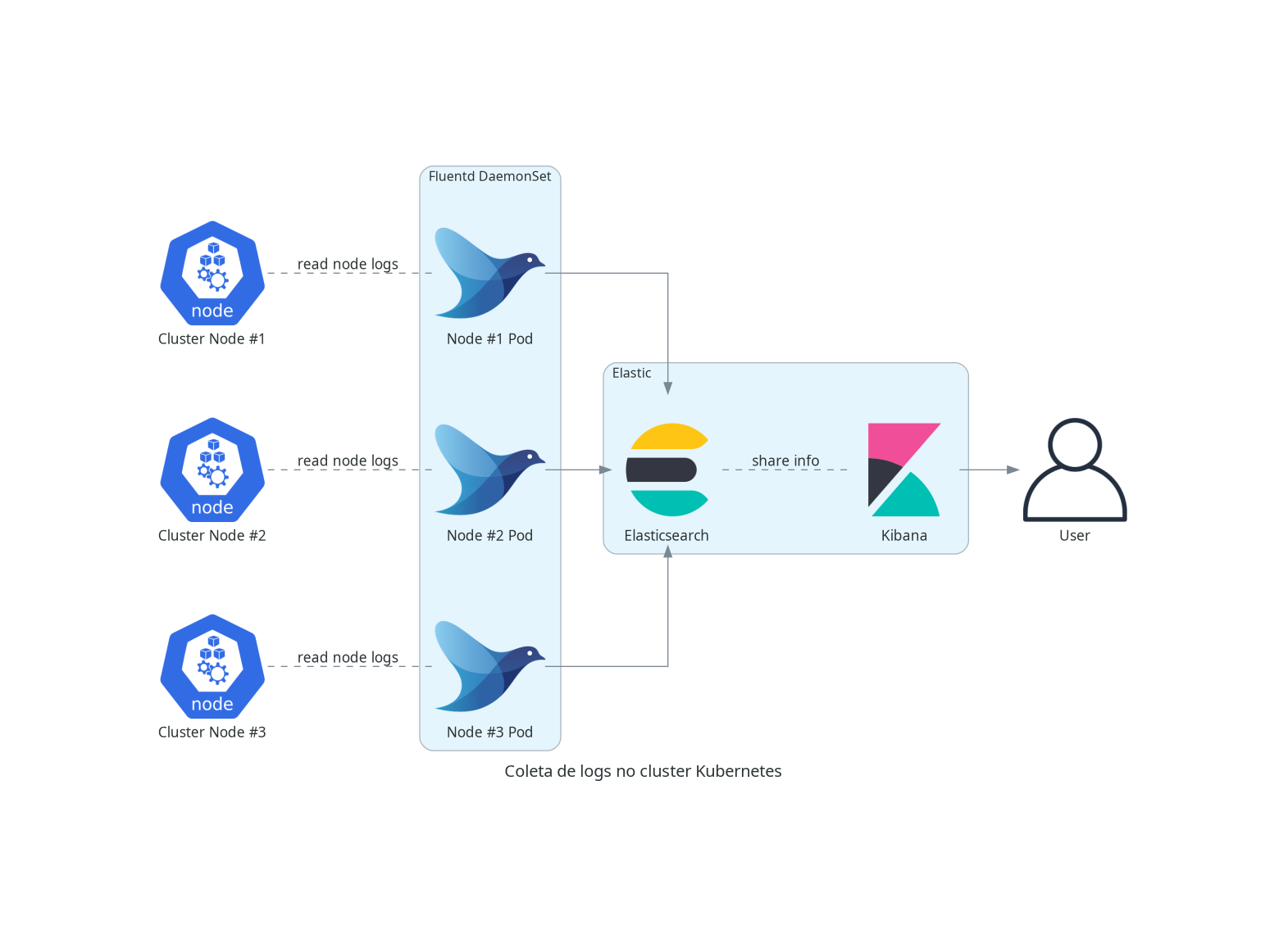
Também é possível utilizar o Grafana para realizar a criação de dashboards com dados do Elasticsearch, porém será necessário adicioná-lo como fonte de dados nas configurações do Grafana, pois isso não é feito por padrão.
Para maiores informações, veja como utilizar o ElasticSearch para verificar logs.
Diagramas de Arquitetura
A seguir, serão listados diagramas da arquitetura do sistema, ligados à disciplina de Engenharia de Software. Por questões de utilidade e por se tratarem de verdadeiros guias para implementação de novas funcionalidades, foi escolhido que essa documentação possuísse apenas diagramas de caso de uso e diagramas de sequência relacionados às regras de negócio de cada domínio da aplicação, o que traduz-se mais ou menos como sendo as funcionalidades individuais de cada microsserviço.
Diagramas de Casos de Uso
Os diagramas a seguir representam casos de uso para o sistema. Esses diagramas não têm a pretensão de serem completos, mas sim de ilustrar funcionalidades esperadas para o sistema, de forma visual.
Os casos de uso foram subdivididos em domínios, que poderão ilustrar os microsserviços envolvidos.
Sessão

Usuários

Inquilinos

Auditoria

Relatórios

Produtos

Estoque

Clientes

Comunicação Instantânea

Diagramas de sequência
As seções a seguir enumeram diagramas de sequência. Esses diagramas representam visualmente informações a respeito das operações realizadas para cada ação que a eles der título, e são de grande ajuda no momento do projeto do sistema.
Os diagramas a seguir foram gerados automaticamente através de PlantUML.
Diagramas de Sequência: Sessão
Os diagramas a seguir dizem respeito ao fluxo de gerenciamento da sessão de um usuário do sistema.
A gerência da sessão assume que os dados do usuário possam ou não serem encontrados no banco de dados. Dito isso, não é incumbência da sessão realizar operações CRUD como usuários, e sim com a entidade da sessão em si.
Login do usuário

Logoff do usuário

Diagramas de Sequência: Usuários
Os diagramas a seguir dizem respeito ao fluxo de gerenciamento de usuários no sistema.
A gerência de usuários não diz respeito à sessão em si.
Cadastro de usuários

Listagem de usuários

Consultar usuário

Alteração do cadastro de usuários

Remoção de usuários

Compilação
Este capítulo fala a respeito das formas de compilação do sistema.
Para compilar e executar a aplicação, vamos utilizar recursos da máquina (em caso de situações envolvendo desenvolvimento) ou teste de aplicação usando Docker.
A geração de imagens Docker é particularmente importante para a realização de testes e deploy posteriores, o que será abordado no próximo capítulo.
Compilando e executando com recursos da máquina
Você pode compilar os módulos do sistema individualmente e executá-los usando o próprio ambiente Rust.
Introdução
Este artigo trata da situação mais comum durante o desenvolvimento das partes do sistema, que envolve utilizá-las individualmente em um ambiente de desenvolvimento.
O deploy usando Docker Compose e Kubernetes, enquanto possível em ambiente de homologação e de testes manuais, utiliza muitos recursos da máquina, e não é o ideal de ser utilizado enquanto o programador estiver debugando a aplicação. Além disso, pela própria forma como o sistema foi planejado, é possível executar porções individuais do sistema em que haja interdependência entre elas.
Objetivo
Compilar todos os módulos ou módulos individuais é muito importante do ponto de vista do desenvolvimento. Neste artigo, tratamos de como isso pode ser feito na máquina local de um desenvolvedor.
Dependências
Você precisará de:
- Rust (compilador
rustce gerenciador de pacotescargo, versão 1.60.0 ou superior); - Diesel (versão 1.4.1 ou superior, com suporte a PostgreSQL);
- Flutter (versão 3.0.0 ou superior, canal
stable. Apenas necessário o target de compilação paraweb); - Dart (versão 2.17.0 ou superior, canal
stable); - Docker (versão 2.10 ou superior).
O compilador Rust e o Docker são essenciais para compilar os módulos individuais do back-end do projeto, enquanto o Flutter é importante para a confecção do front-end da aplicação. Sendo assim, as dependências podem ser instaladas de acordo com o bom-senso do desenvolvedor.
O Diesel pode ser instalado através do gerenciador de pacotes cargo,
e sua instalação pode ser consultada em seu site, linkado acima. Além
disso, a linguagem Dart será instalada através do Flutter, de acordo
com as instruções que podem ser encontradas no site do mesmo.
Estrutura do projeto
O repositório do projeto é um monorepo, isto é, engloba todas as
partes do sistema inteiro. Por isso, as partes relacionadas a back-end
estão dispostas em um Workspace, configurável através das próprias
ferramentas do cargo e da linguagem Rust, enquanto o front-end
encontra-se unicamente no diretório minerva_frontend, e não faz
parte do Workspace em si.
Preparação do ambiente
A primeira parte a ser executada deverá ser a preparação do ambiente. Isso inclui a preparação de quaisquer serviços ou bancos de dados externos que possam ser importantes para a execução da aplicação.
No Sistema Minerva, o serviço RUNONCE é responsável por executar
essas operações, sendo também o serviço que executa migrations no
banco de dados, por exemplo.
Para tanto, precisaremos compilar este módulo específico antes de qualquer outro. Isso será melhor delineado na seção sobre compilação do back-end, mas realizaremos uma configuração rápida nesta seção.
Criando recursos locais com Docker
Para executar localmente, o sistema precisa que alguns serviços sejam instanciados antes de sua execução.
É importante lembrar que os métodos a seguir não são considerados seguros para persistência de dados. Por isso, use-os apenas com a finalidade de testes.
Usando recursos por meio externo (Kubernetes)
Caso você não queira executar os serviços essenciais
mais pesados em termos de recursos (PostgreSQL, MongoDB, Redis e
RabbitMQ), poderá reaproveitá-los caso tenha realizado deploy dos
mesmos em Kubernetes. Para tanto, você poderá usar um script
preparado que realiza esse processo. Veja que esse script assume
que você possua a ferramenta kubectl com acesso padrão configurado
para o cluster que seja seu target.
O script encontra-se excepcionalmente em helpers/port-forwards.sh,
na raiz do projeto.
Banco de dados relacional
Como primeira dependência, recomenda-se criar o banco de dados relacional via Docker. Também seria possível instalar o PostgreSQL 15 na máquina local, mas o Docker provê a comodidade necessária para o BD.
Para subir o banco de dados relacional, execute o script make_postgres_db.sh
no diretório minerva-runonce, ou execute:
docker run --name minerva-postgres \
-e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=postgres \
-p 5432:5432 \
-d postgres:15-alpine
O contêiner poderá então ser gerenciado através do Docker, como um contêiner qualquer.
Banco de dados não-relacional
Recomenda-se também criar o banco de dados não-relacional via Docker. Igualmente, é possível instalar o MongoDB 4 por métodos convencionais.
Veja que o MongoDB é usado aqui em sua versão 4 especialmente por ser mais compatível com ambientes IoT, em especial K3s executando em um Raspberry Pi 4 Model B, que foi utilizado para testar o deploy em um cluster Kubernetes.
Para subir o banco de dados não-relacional, execute o script
make_mongo_db.sh no diretório minerva-runonce, ou execute:
docker run --name minerva-mongo \
-e MONGO_INITDB_ROOT_USERNAME=root \
-e MONGO_INITDB_ROOT_PASSWORD=mongo \
-p 27017:27017 \
-d mongo:4
Como esperado, o contêiner pode ser gerenciado normalmente através do Docker.
Banco de dados in-memory (cache)
Para o uso do serviço de cache, recomenda-se usar diretamente o Redis através
do Docker. Para tanto, execute o script make_redis_db.sh no diretório
minerva-runonce, ou execute:
docker run --name minerva-redis \
-p 6379:6379 \
-d redis:7-alpine
Assim como antes, gerencie o contêiner criado usando o Docker.
Broker de mensagens (com gerenciador)
O message broker RabbitMQ deverá também ser executado através do Docker. Para a execução do mesmo, todavia, atente-se para o uso de memória elevado que essa ferramenta possui.
Você poderá executar o script make_rabbitmq.sh no diretório
minerva_runonce, ou simplesmente executar:
docker run --name minerva-rabbitmq \
-e RABBITMQ_DEFAULT_USER=rabbitmq \
-e RABBITMQ_DEFAULT_PASS=minerva \
-p 15672:15672 \
-p 5672:5672 \
-d rabbitmq:3-management-alpine
Executando configuração inicial (módulo RUNONCE)
A seguir, execute o módulo RUNONCE para preparar todos os bancos de
dados de tenants, executar as migrations, criar o usuário admin
em cada banco e outras operações em outros serviços também.
Você poderá executar o módulo diretamente a partir da raiz do projeto:
cargo run --bin minerva-runonce
Caso haja algum problema com o comando anterior (por exemplo, se o
módulo não encontrar o diretório migrations), vá para o diretório do
módulo e execute-o:
cd minerva-runonce
cargo run
Após a compilação do módulo RUNONCE, o mesmo aguardará o banco de
dados estar pronto para receber as conexões e aplicará as migrations.
Compilação (Back-end)
Você poderá compilar todos os módulos do projeto de uma só vez, ou compilar apenas os módulos necessários.
Compilando todos os módulos
Para compilar todos os módulos, vá para a raiz do projeto e execute um comando de compilação para todo o workspace:
cargo build
De forma similar, você poderá compilar o projeto para produção através
da flag --release:
cargo build --release
Compilando um módulo específico
Existem duas formas de compilar um módulo específico: a partir do workspace (diretório raiz do repositório) ou a partir do diretório do módulo específico.
Qualquer módulo pode ser compilado a partir do diretório raiz com um
comando como o mostrado a seguir (substitua <módulo> pelo nome do
diretório do módulo em questão):
cargo build --bin <módulo>
Isto compilará qualquer módulo que faça parte do workspace, exceto
bibliotecas auxiliares (como minerva-rpc, minerva-data e
minerva-cache) e o front-end (contido em minerva_frontend).
Da mesma forma, você também poderá ir ao diretório do módulo específico e compilá-lo diretamente; neste caso, a compilação também funcionará para bibliotecas auxiliares.
cd <módulo>
cargo build
De forma similar à compilação geral, ambos os comandos também admitem
a flag --release para compilar os módulos para produção.
Execução
É possível executar diretamente um módulo qualquer através do cargo,
o que também implica na sua compilação.
Para executar a partir do diretório do workspace (apenas para módulos que geram executáveis):
cargo run --bin <módulo>
Para executar a partir do diretório do módulo em questão:
cd <módulo>
cargo run
Da mesma forma, é possível compilar e executar os módulos no modo
de produção através da flag --release.
Testes
Para executar testes unitários e integração, basta seguir um processo
similar à execução dos módulos. Testes com binários compilados para
produção podem ser igualmente controlados pela flag --release.
Para executar quaisquer testes, é necessário garantir que o banco de dados esteja acessível e adequadamente configurado.
# Para testar todos os módulos do workspace
cargo test
# Para testar apenas um módulo do workspace
cargo test --bin <módulo>
# Para testar apenas um módulo em seu diretório
cd <módulo>
cargo test
Compilação (Front-end)
O front-end é um módulo separado do restante dos módulos, sendo o sistema que envolve a interface gráfica do Sistema Minerva.
Executando o projeto via console
Para executar o projeto via console, basta usar a ferramenta de linha de comando do Flutter.
Preparando o Flutter
Antes de mais nada, garanta que o Flutter esteja configurado para compilar projetos Web:
flutter config --enable-web
Além disso, o Google Chrome deverá estar disponível para ser utilizado
no debug. O estado do ambiente Flutter pode ser verificado com o
comando flutter doctor.
Caso haja alguma inconsistência no seu ambiente, veja a seção de preparação do Flutter para Web na documentação oficial.
Executando o projeto
Para executar o projeto, vá até o diretório do módulo de front-end, baixe as dependências necessárias, e então execute o projeto no Google Chrome:
cd minerva_frontend
flutter pub get
flutter run -d chrome
Compilando para produção
Para compilar o projeto para produção, vá até a pasta do módulo e execute os comandos a seguir. Eles baixarão as dependências faltantes (caso já não tenham sido baixadas) e gerarão os arquivos estáticos da aplicação.
cd minerva_frontend
flutter pub get
flutter build web
Você poderá encontrar a versão compilada da aplicação front-end no
diretório minerva_frontend/build/web.
Gerando imagens via Docker
Script para geração de imagens
Já existe um script separado para a geração das imagens (com tags apropriadas). Para gerá-las, vá até a raiz do repositório e execute o comando:
./generate_images.sh
Esse script foi especialmente feito para um console Bash, e pensado para execução no Linux. No entanto, caso você esteja no Windows, poderá executá-lo via Git Bash, MSYS2 ou similar, desde que seja possível utilizar o Docker através da linha de comando.
Gerando uma imagem em específico
Caso seja necessário, você poderá gerar uma imagem em específico de um projeto.
Para qualquer projeto, poderá executar o seguinte comando a partir da raiz do repositório:
docker buildx build \
-f build/Dockerfile \
--target minerva_<projeto> \
-t seu_username/minerva_<projeto>:latest \
.
Lembre-se de substituir <projeto> pelo projeto em questão.
Criando uma tag para a imagem
Todas as imagens são geradas automaticamente com tags de acordo com o projeto
do qual está sendo gerado (arquivos Cargo.toml e pubspec.yaml).
Se você estiver gerando as imagens manualmente, poderá definir uma tag como no exemplo a seguir:
# Faça algo similar para cada uma das imagens
docker image tag \
seu_username/minerva_user \
seu_username/minerva_user:0.2.0
Nomes e tags das imagens geradas
As imagens geradas pelos passos anteriores são geradas com nomes específicos. Esses nomes serão muito úteis do ponto de vista do envio dessas imagens para o DockerHub e do deploy via Docker Compose, Docker Swarm e Kubernetes.
As imagens são sempre geradas com a tag latest, mas também
receberão tags de acordo com seus arquivos de projeto (Cargo.toml
e pubspec.yaml).
A seguir, temos uma tabela relacionando os serviços com os nomes e tags
das imagens geradas. Veja que elas se relacionam, inclusive, com a forma
como essas imagens encontram-se no DockerHub (sob o username luksamuk):
| Serviço | Nome e tag da imagem |
|---|---|
frontend | luksamuk/minerva_frontend:latest |
rest | luksamuk/minerva_rest:latest |
runonce | luksamuk/minerva_runonce:latest |
user | luksamuk/minerva_user:latest |
session | luksamuk/minerva_session:latest |
| -------------- | -------------------------------------- |
pgadmin | dpage/pgadmin4:latest (Não gerado) |
postgresql | postgres:15 (Não gerado) |
mongodb | mongo:4 (Não gerado) |
Subindo imagens para o DockerHub
Para enviar uma imagem para o DockerHub, primeiro é necessário se certificar de que essa imagem possua uma tag adequada.
Em seguida, poderemos enviar todas as tags das imagens para o DockerHub.
docker image push -a luksamuk/minerva_frontend
docker image push -a luksamuk/minerva_rest
docker image push -a luksamuk/minerva_runonce
docker image push -a luksamuk/minerva_user
docker image push -a luksamuk/minerva_session
Geração de imagens cross-platform
O script generate_and_push.sh gera imagens cross-platform e de forma
otimizada, sendo o script preerido a ser executado para enviar imagens para
o DockerHub.
Use esse script se a intenção for compilar para mais arquiteturas ou gerar versão oficial, de forma otimizada.
SonarQube e Quality Gates
O projeto Minerva System atualmente está hospedado no GitHub e, por isso, utiliza as ferramentas de pipelines e CI/CD do mesmo para execução de testes e geração de builds.
Para garantir a qualidade no processo de entrega de cada pull request, foi
adicionado suporte a SonarQube, principalmente através do arquivo
sonar-project.properties que se encontra na raiz desse projeto.
O GitHub possui acesso ao SonarQube, que está em execução em infraestrutura própria que, por enquanto, trata-se de um servidor on-premise em um Raspberry Pi 4, mais especificamente executando K3s (uma implementação de Kubernetes). Este servidor também opera atualmente como o ambiente de testes do Minerva System, uma vez que o mesmo não possui um ambiente de QA ou produção.
Por isso, pelo menos por enquanto, o projeto não possui um portal de métricas explícito que possa ser acompanhado por desenvolvedores.
Para que um pull request passe nos quality gates do projeto, ele deverá garantir que o código possua as seguintes estatísticas:
| Estatística | Valor para falha |
|---|---|
| Cobertura de testes | Menor que 50%* |
| Linhas duplicadas (%) | Maior que 3%* |
| Code Smells | Maior que 0 |
| Vulnerabilidades | Maior que 0 |
As estatísticas marcadas com * estão sujeitas a mudança no futuro. Idealmente,
o código deverá ter uma cobertura de no mínimo 80% e a quantidade de linhas
duplicadas poderá ser diminuída após mais análise.
Deploy
As sessões a seguir tratarão do deploy da aplicação, ou mais especificamente, de formas escaláveis de subir a aplicação num ambiente que simule produção.
Este capítulo trata de três tipos específicos de deploy:
- Usando Docker Compose;
- Usando Docker Swarm;
- Usando Kubernetes, através do Minikube.
O Docker Compose poderá ser utilizado em situações de teste e desenvolvimento,
especialmente porque seu arquivo de configuração sempre aponta para a imagem
com tag latest de todos os contêineres (o que significa que utilizará
as imagens que tiverem sido recém-geradas na máquina).
O Docker Swarm trabalha de forma similar ao Compose em sua configuração, porém
utilizaremos a ferramenta docker stack, além de certa configuração manual,
para subir um cluster com docker-machine, que pode também ser configurado de
forma doméstica. A configuração poderá então ser usada para orquestração de
contêineres.
Já o Kubernetes, utilizando uma máquina virtual KVM2 através do Minikube, possibilita uma orquestração de contêineres ainda mais flexível. Esta configuração é utilizada também para um ambiente local, mas será a forma mais próxima de colocar o sistema em produção.
Deploy usando Docker Compose

Você pode realizar deploy do projeto usando Docker Compose. Todavia, esta não é a forma mais recomendada de realização de deploy.
Introdução
Docker Compose é uma ferramenta simples de orquestração de contêineres. Para o Minerva System, é principalmente uma forma de testar a forma como o serviço se comporta em rede.
Objetivo
O deploy usando Docker Compose é útil principalmente do ponto de vista da geração das imagens das aplicações dos microsserviços do Minerva System, mas também não é a forma mais recomendada de colocar o sistema em produção, porque não prevê fatores de escalabilidade como o deploy usando Kubernetes.
Utilize esta forma principalmente quando quiser avaliar o comportamento do sistema no que tange a interconexões entre os serviços numa rede virtual.
Dependências
Você precisará ter:
- Docker versão 20.10 ou superior;
- Docker Compose versão 2.2.3 ou superior;
- As imagens do projeto (se não estiverem localmente disponíveis, serão baixadas).
Além disso, todos os comandos a seguir devem ser executados no
diretório deploy/coompose deste projeto.
Preparando-se para a execução dos serviços
Primeiramente, você deverá se preparar para a geração de arquivos de
log em cada serviço. Para tanto, no Linux, execute o script make_log_dir.sh.
Esse script criará uma pasta log que será montada para o usuário
com UID 1000, correspondente ao usuário appuser na maioria das imagens
dos serviços do Minerva System.
Executando dependências
O Minerva System depende essencialmente de quatro serviços de terceiros:
- PostgreSQL;
- MongoDB;
- Redis;
- RabbitMQ.
É possível realizar a execução desses serviços através de algum provedor que os facilite, mas, para eventuais testes locais, você poderá usar uma configuração de Docker Compose específica ou utilizar diretamente esses serviços caso estejam hospedados em um cluster Kubernetes, através de port-forward.
Executando via Docker Compose
Para executar os serviços na máquina atual, você deverá navegar até
a pasta services e iniciar o Docker Compose:
cd services
docker compose up
Os serviços estarão expostos nas seguintes portas:
| Porta | Serviço |
|---|---|
| 8484 | PgAdmin 4 |
| 8686 | Mongo Express |
| 8787 | Redis Commander |
| 5672 | RabbitMQ (Serviço) |
| 15672 | RabbitMQ (Gerenciador) |
O gerencialmento funcionará de forma similar aos serviços em si, portanto, para maiores informações sobre o uso do Compose, veja a seção Executando os serviços.
Usando Port Forward do Kubernetes
Caso você não queira executar os serviços essenciais
mais pesados em termos de recursos (PostgreSQL, MongoDB, Redis e
RabbitMQ), poderá reaproveitá-los caso tenha realizado deploy dos
mesmos em Kubernetes. Para tanto, você poderá usar um script
preparado que realiza esse processo. Veja que esse script assume
que você possua a ferramenta kubectl com acesso padrão configurado
para o cluster que seja seu target.
O script encontra-se excepcionalmente em helpers/port-forwards.sh,
na raiz do projeto.
Executando os serviços
Para executar os serviços usando Docker Compose, use o seguinte comando:
docker compose up
Caso você queira desligar o funcionamento dos serviços da sessão atual do console, poderá executá-los em forma de daemon:
docker compose up -d
Neste caso em específico, para localhost, estarão abertas as
seguintes portas para acesso aos serviços:
| Porta | Serviço |
|---|---|
| 9000 | API REST (endpoint /api) |
| 9010 | USER |
| 9011 | SESSION |
Acompanhando logs
Para acompanhar os logs de um deploy via daemon ou de um outro console, você poderá realizá-lo através do comando:
docker compose logs -f
Caso seja necessário acompanhar os logs de apenas um serviço:
docker compose logs -f <servico>
Lembre-se de que o nome do serviço em questão deverá ser informado
como listado em docker-compose.yml.
Reiniciando um único serviço
Você poderá reiniciar um único serviço, caso tenha recompilado a imagem do mesmo, por exemplo.
Nesse caso, basta usar o seguinte comando:
docker compose up -d --no-deps <servico>
Caso você queira incluir o passo de recompilação da imagem:
docker compose up -d --no-deps --build <servico>
Encerrando os serviços
Para encerrar imediatamente o serviço, execute o seguinte comando:
docker compose down
Caso você queira também remover os volumes associados aos serviços (por exemplo, nocaso do PostgreSQL e do pgAdmin), use este comando em vez do anterior:
docker compose -v down
Deploy via Docker Swarm + Vagrant

Além do deploy via Docker Compose, também é possível disponibilizar a stack do Sistema Minerva em um cluster do Docker Swarm.
Para tanto, é necessário inicializar o cluster. Isso pode ser feito, por exemplo, com máquinas virtuais para finalidade de teste (neste caso, pode ser utilizado o VirtualBox para prover essa facilidade).
Nesse capítulo, veremos como fazer isso de forma automatizada através de uma configuração do Vagrant. Essa configuração criará máquinas virtuais e também inicializará o sistema no cluster.
Pré-requisitos
- Vagrant versão 2.2.19 ou superior;
- VirtualBox versão 6.1 ou superior.
Você pode utilizar outro provider além de VirtualBox (como libvirt), mas
precisará alterar o arquivo Vagrantfile.
NOTA: Qualquer comando do Vagrant deve ser executado no diretório
deploy/swarm, para que o Vagrant tenha acesso ao Vagrantfile.
Reinicializando o cluster
Caso você já tenha iniciado o cluster com Vagrant, basta ir até o diretório
deploy/swarm e executar vagrant up. Isso reiniciará as máquinas virtuais,
mas também executará o docker stack deploy novamente para o arquivo de
configuração, o que forçará uma atualização em todos os serviços.
Criando o cluster
Para criar o cluster, vá até o diretório deploy/swarm e execute o Vagrant.
cd deploy/swarm
vagrant up
Isso utilizará o arquivo Vagrantfile para criar sete máquinas virtuais
(dois managers e dois workers), e também realizará automaticamente o
deploy do sistema Minerva usando o arquivo docker-stack.yml.
Alguns arquivos extras serão criados na pasta. Eles dizem respeito respectivamente ao IP do primeiro gerente e aos tokens de ingresso no cluster para gerentes e trabalhadores.
Em geral, a relação das máquinas virtuais do cluster será:
manager01: Manager, líder, inicializador original dos serviços;manager02emanager03: Managers adicionais;worker01aworker04: Workers.
Para verificar o formato do cluster e as informações acima, use o comando:
vagrant status
Fazendo deploy do Sistema Minerva
Caso você realize modificações no arquivo docker-stack.yml, poderá
querer fazer deploy novamente dos serviços de forma manual.
Para tanto, entre em qualquer um dos managers via SSH. Por exemplo, para o primeiro manager:
vagrant ssh manager01
O diretório deploy/swarm fica montado dentro de todas as máquinas virtuais
em /vagrant (que é mutável apenas durante a criação do cluster). Todavia,
você ainda poderá modificar os arquivos no host e terá acesso a eles.
Para aplicar manualmente o arquivo docker-stack.yml:
# Em manager01
docker stack deploy --compose-file /vagrant/docker-stack.yml minerva
Gerenciando a stack
Podemos gerenciar a stack facilmente dentro de uma VM manager.
Para listar as stacks ativas:
# Em manager01
docker stack ls
Se quisermos observar os serviços de uma stack em específico:
# Em manager01
docker stack services minerva
Ou, em último caso, se quisermos remover uma stack:
# Em manager01
docker stack rm minerva
Acessando os serviços
Os serviços que podem ser acessados de forma externa estarão disponíveis normalmente assim como no Docker Compose, porém sob um IP diferente.
Por padrão, todos os managers possuem um IP começado com 172.20.20.1X,
algo definido através do Vagrantfile. Os workers terão um IP
iniciado com 172.20.20.10X. A variável X será sempre um número
contado a partir de 1.
Seguindo essas regras, as VMs possuirão os seguintes IPs:
| IP | Hostname |
|---|---|
| 172.20.20.11 | manager01 |
| 172.20.20.12 | manager02 |
| 172.20.20.13 | manager03 |
| 172.20.20.101 | worker01 |
| 172.20.20.102 | worker02 |
| 172.20.20.103 | worker03 |
Para acessar os serviços, use qualquer IP do cluster. A descoberta do serviço será realizada através do routing mesh do Docker Swarm.
Abaixo, temos uma relação das portas utilizadas para cada um dos serviços disponíveis no cluster.
| Porta | Serviço |
|---|---|
| 80 | Front-End |
| 9000 | API REST |
| 8484 | PgAdmin 4 |
| 8585 | Visualizador do cluster |
| 8686 | Mongo Express |
| 8787 | Redis Commander |
| 5672 | RabbitMQ (Serviço) |
| 15672 | RabbitMQ (Gerenciador) |
Encerrando o serviço
Para encerrar todas as máquinas virtuais sem perder o estado das mesmas, use:
vagrant suspend
Ou, se você desejar destruir o cluster completamente:
vagrant destroy -f
Deploy via Docker Swarm + Docker Machine

Outra forma de realizar deploy usando o Docker Swarm é através do Docker Machine, um utilitário capaz de criar máquinas virtuais com Docker já instalado a partir de uma imagem Linux especial.
O Docker Machine é uma ferramenta defasada, mas pode ser uma alternativa quando for do interesse do programador fazer um trabalho mais manual. Por ser o método utilizado antes do uso do Vagrant, esta página existe como referência ao uso da ferramenta.
Pré-requisitos
- Docker Machine versão 0.16.2;
- VirtualBox versão 6.1 ou superior.
Instalando o Docker Machine no Linux
Como o Docker Machine é uma ferramenta defasada, é necessário executar passos como os a seguir para instalar:
base=https://github.com/docker/machine/releases/download/v0.16.2
curl -L $base/docker-machine-$(uname -s)-$(uname -m) >/tmp/docker-machine
sudo install /tmp/docker-machine /usr/local/bin/docker-machine
Para instalar os drivers de KVM2, caso você prefira utilizá-los:
base=https://github.com/praveenkumar/machine-kvm2-driver/releases/download/v0.11.0
curl -L $base/docker-machine-driver-kvm2 >/tmp/docker-machine-driver-kvm2
sudo install /tmp/docker-machine-driver-kvm2 /usr/local/bin/docker-machine-driver-kvm2
Reinicializando o cluster
Caso você já tenha construído um cluster e feito deploy via Docker Machine anteriormente, é bem provável que você não precise fazer a maioria do trabalho. Você poderá simplesmente reiniciar as máquinas virtuais:
docker-machine start `docker-machine ls "minerva-*" -q`
Existe a possibilidade de as máquinas virtuais não conseguirem se reconhecer por uma mudança de IP. Se isso ocorrer, reconfigure o cluster manualmente, gerando os tokens para cada máquina virtual e inserindo-as no cluster.
Criando o cluster
Se você ainda não tiver um cluster criado, poderá criar o cluster através
da ferramenta Docker Machine. Comece criando uma máquina virtual chamada
minerva-vm1, que será nosso inicializador do cluster.
docker-machine create -d virtualbox --swarm-master minerva-vm1
Iniciando o cluster
Vamos começar iniciando o Docker Swarm na primeira máquina virtual.
Para acessar o console de uma máquina virtual via SSH, use também o Docker Machine para isso.
docker-machine ssh minerva-vm1
Para iniciar o cluster, precisamos descobrir também o IP dessa máquina virtual. Você poderá ver o IP de uma máquina virtual em específico via Docker Machine também, em outro console:
docker-machine ip minerva-vm1
Voltando ao console da VM, vamos iniciar o Docker Swarm.
# Em minerva-vm1
docker swarm init --advertise-addr <IP>
Criando mais managers
Uma arquitetura básica de managers e workers do Swarm, para que o algoritmo de consenso RAFT opere como esperado, poderia envolver três managers e dois workers -- portanto, cinco máquinas virtuais.
Vamos criar mais duas máquinas virtuais que vão servir de managers (minerva-vm2
e minerva-vm3):
docker-machine create -d virtualbox --swarm-master minerva-vm2
docker-machine create -d virtualbox --swarm-master minerva-vm3
Para adicionar essas VMs no cluster, vamos obter o token de entrada no cluster para managers, que será um mero comando do console. Copiamos esse comando e colamos no console das duas máquinas virtuais recém-criadas.
# Em minerva-vm1
docker swarm join-token manager
# Em minerva-vm2 e minerva-vm3: Cole o comando
docker swarm join --token...
Criando workers
Criaremos mais duas máquinas virtuais com o Swarm preparado, mas dessa vez, vamos prepará-las para serem meros workers:
docker-machine create -d virtualbox --swarm minerva-vm4
docker-machine create -d virtualbox --swarm minerva-vm5
O princípio para adicionar workers no cluster é o mesmo, porém usaremos um comando
diferente para gerar o token. Geramos esse comando, copiamos e colamos no console
das VMs minerva-vm4 e minerva-vm5.
# Em minerva-vm1
docker swarm join-token worker
# Em minerva-vm4 e minerva-vm5: Cole o comando
docker swarm join --token...
Verificando a topologia do cluster
Vamos verificar a topologia do cluster. Podemos observar a atividade das máquinas virtuais diretamente através do Docker Machine:
docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
minerva-vm1 - virtualbox Running tcp://192.168.99.108:2376 v19.03.12
minerva-vm2 - virtualbox Running tcp://192.168.99.109:2376 v19.03.12
minerva-vm3 - virtualbox Running tcp://192.168.99.110:2376 v19.03.12
minerva-vm4 - virtualbox Running tcp://192.168.99.111:2376 v19.03.12
minerva-vm5 - virtualbox Running tcp://192.168.99.112:2376 v19.03.12
Para avaliarmos o cluster em si e a forma como os nós se conectam, poderemos ver a topologia dos nós diretamente dentro da primeira VM:
# Em minerva-vm1
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
exgmsiju6pnrl01tt33n5guui * minerva-vm1 Ready Active Leader 19.03.12
cpxtnhalvu9tat9ek4n1n0117 minerva-vm2 Ready Active Reachable 19.03.12
p2v7v8ac93wuhwhcdsjl00p8y minerva-vm3 Ready Active Reachable 19.03.12
jihrf6wgm145xzr0pdb6tnrck minerva-vm4 Ready Active 19.03.12
b1wfgme22m14pmjceo8ktn1hj minerva-vm5 Ready Active 19.03.12
Outra opção interessante é acompanhar também os serviços e os contêineres criados:
# Em minerva-vm1
docker service ls
docker container ls
Fazendo backup do cluster
Caso você queira fazer backup da topologia do cluster, lembre-se de copiar o
diretório /var/lib/docker/swarm em minerva-vm1.
# Em minerva-vm1
sudo cp -r /var/lib/docker/swarm ./swarm
sudo chown -R $USER ./swarm
# No host
docker-machine scp -r minerva-vm1:/home/docker/swarm localhost:~/swarm-backup
Fazendo deploy do Sistema Minerva
Para fazer deploy do sistema, dado que o cluster esteja configurado, basta reutilizar o arquivo preparado para isso no repositório do Sistema Minerva.
Copiamos o arquivo para dentro da VM principal e então realizamos deploy:
docker-machine scp localhost:./deploy/swarm/docker-stack.yml minerva-vm1:/home/docker/docker-stack.yml
# Em minerva-vm1
docker stack deploy --compose-file docker-stack.yml minerva
Gerenciando a stack
Podemos gerenciar a stack facilmente dentro de uma VM manager.
Para listar as stacks ativas:
# Em minerva-vm1
docker stack ls
Se quisermos observar os serviços de uma stack em específico:
# Em minerva-vm1
docker stack services minerva
Ou, em último caso, se quisermos remover uma stack:
# Em minerva-vm1
docker stack rm minerva
Acessando os serviços
Para visualizar os serviços, primeiro visualize o IP das Docker Machines:
docker-machine ls
É possível usar o IP de qualquer Docker Machine, neste ponto. Basta utilizar as portas certas:
| Porta | Serviço |
|---|---|
| 80 | Front-end |
| 9000 | API REST |
| 8484 | PgAdmin 4 |
| 8585 | Visualizador do cluster |
| 8686 | Mongo Express |
| 8787 | Redis Commander |
| 5672 | RabbitMQ (Serviço) |
| 15672 | RabbitMQ (Gerenciador) |
Encerrando o serviço
Caso você queira parar todas as máquinas virtuais, use o comando a seguir:
docker-machine stop `docker-machine ls "minerva-*" -q`
Ou, se você quiser remover realmente as máquinas virtuais:
docker-machine rm `docker-machine ls "minerva-*" -q`
Deploy usando Kubernetes
Você pode realizar deploy do projeto usando Kubernetes. Nos passos a seguir, será mostrado como realizar deploy em um ambiente Kubernetes.
É importante salientar também que o deploy do Minerva System geralmente é feito em um ambiente K3s, o que pode impactar em algumas formas de configuração.
Introdução
Kubernetes é uma ferramenta sofisticada de orquestração de contêineres. O Minerva System é planejado para que seu deploy seja feito utilizando o Kubernetes.
Objetivo
O deploy usando Kubernetes é planejado desde o início do projeto, sendo uma das formas de estado da arte de deploy de aplicações web. Para simular este cenário, utilizamos uma instalação em um cluster local com K3s, em computadores cuja arquitetura seja x86_64 ou ARM64.
Dependências
As configurações de deploy são preparadas de forma a utilizar o próprio registry do DockerHub como fonte para as imagens previamente geradas. Assim, é necessário apenas ter acesso a um cluster com Kubernetes instalado, algo que pode ser simulado através da ferramenta K3s.
Para monitoramento e configuração, use as ferramentas a seguir:
- Kubectl v 1.23.3 ou superior, de acordo com o compatível com seu cluster;
- k9s versão 0.25.18 ou superior, para monitoramento (opcional);
- kubernetes-el, pacote do editor de texto Emacs que permite monitorar um cluster Kubernetes.
A instalação local do K3s é opcional, e poderia ser substituída pelo Minikube, porém essa substituição pode ser impactante na configuração de alguns recursos, especialmente em Ingresses.
Realizando deploy de serviços
Nos passos a seguir, será mostrado como realizar deploy de cada um dos serviços e objetos k8s que fazem parte do Minerva System. Recomenda-se seguir os tópicos em ordem.
Os passos também assumem que a ferramenta kubectl esteja configurada
localmente e que tenha acesso ao cluster.
Geralmente, o kubectl lê a configuração em ~/.kube/config por padrão;
caso sua máquina não possua esse arquivo, verifique se consegue obter a
configuração do Kubernetes para substituí-lo. No caso do K3s, esse arquivo
está em /etc/rancher/k3s/k3s.yaml, e pode ser copiado, de forma
paliativa, para uma outra máquina, desde que o host do cluster seja adequado
na chave server.
Dependências iniciais
Para realizar o deploy do Minerva System, primeiramente precisaremos provisionar as dependências iniciais, software externos que são utilizados pelo resto do sistema.
Namespace do sistema
O namespace deve ser aplicado para que todos os objetos do sistema existam dentro do mesmo. Assim, temos uma forma de encapsular o sistema inteiro com a maior parte de suas dependências.
kubectl apply -f minerva-namespace.yml
PostgreSQL
O próximo passo é realizar o deploy do banco de dados relacional. O Minerva System usa PostgreSQL para tanto. A configuração envolve um Secret, um PersistentVolumeClaim, um Deployment, e um Service de tipo ClusterIP para garantir que o mesmo só possa ser acessado dentro do cluster.
kubectl apply -f postgresql.yml
MongoDB
Para banco de dados não-relacional, utilizaremos o MongoDB. O Minerva System usa o MongoDB principalmente para armazenamento de dados de seção do usuário. A configuração envolve um Secret, um PersistentVolumeClaim, um Deployment, e um Service de tipo ClusterIP, para que o MongoDB só possa ser acessado dentro do cluster.
kubectl apply -f mongodb.yml
Redis
Como serviço de cache, usamos um cluster Redis configurado manualmente. Esse cluster levanta um mínimo de duas instâncias do Redis, de forma que uma instância seja mestre e as demais sejam instâncias que operam como meras réplicas.
O Redis possui um ConfigMap que define um arquivo de configuração para o cluster. Além disso, temos um PersistentVolumeClaim, e o cluster definido através de um StatefulSet Temos também um Service de tipo ClusterIP para que ele possa ser acessado, e um HorizontalPodAutoscaler que adiciona ou remove réplicas sob demanda.
kubectl apply -f redis.yml
RabbitMQ
O Minerva System usa o RabbitMQ para serviços de mensageria.
O RabbitMQ é utilizado majoritariamente para abrigar mensagens de operações que possam ser despachadas de forma assíncrona, sem uma interferência direta do usuário, ou que sejam efeito colateral de outras operações no sistema.
Para provisionar o RabbitMQ, precisamos provisionar um operador de cluster para RabbitMQ, e então criar uma instância de cluster do RabbitMQ, que criará réplicas do serviço de forma eficiente.
Operador de cluster
Para realizarmos o deploy de um operador de cluster, utilizaremos o projeto
RabbitMQ Cluster Operator.
O arquivo para deploy do cluster está reproduzido no repositório; igualmente,
sua licença pode ser encontrada em rabbitmq-cluster-operator.LICENSE.
kubectl apply -f rabbitmq-cluster-operator.yml
Instância do cluster
Agora, para criarmos uma instância do cluster RabbitMQ com três réplicas, podemos aplicar a configuração criada para o Minerva System. Isso criará um StatefulSet e um Service de tipo ClusterIP para o nosso cluster RabbitMQ.
kubectl apply -f broker-rabbitmqcluster
Configuração das dependências
Uma vez que as dependências iniciais estejam preparadas, poderemos configurar os bancos de dados, criar filas de mensagens e preparar tenants.
Configuração geral de Servers e Portas
Inicialmente, precisaremos criar dois ConfigMaps, que registram os hosts e portas dos serviços que serão criados. Essas configurações são compartilhadas pela maioria dos serviços.
kubectl apply -f servers-configmap.yml
kubectl apply -f ports-configmap.yml
Serviço de preparação
Isso pode ser feito através do módulo RUNONCE, composto de um ConfigMap, um Secret e um Job. Ao aplicar sua configuração, o Job será executado e preparará as dependências.
kubectl apply -f minerva-runonce.yml
Módulos do Minerva System
A partir desse momento, podemos começar o deploy dos módulos do Minerva System. Cada um dos módulos é basicamente uma aplicação stateless, sendo geralmente composto de um Deployment, um Service de tipo ClusterIP, e um HorizontalPodAutoscaler que criará ou destruirá réplicas dos Pods sob demanda. Alguns módulos também possuem o próprio ConfigMap para definir algumas variáveis de ambiente necessárias.
USER
O serviço gRPC de gerenciamento de usuários.
kubectl apply -f minerva-user.yml
SESSION
O serviço gRPC de gerenciamento de sessões de usuários.
kubectl apply -f minerva-session.yml
DISPATCH
O serviço de despacho de mensagens vindas do RabbitMQ.
Esse serviço não possui um Service, já que não pode ser acessado diretamente; seu único objetivo é despachar mensagens para outros serviços, de acordo com o que for requisitado através de mensagens via filas no RabbitMQ.
kubectl apply -f minerva-dispatch.yml
REST (Gateway)
O serviço REST funciona como um gateway para o back-end do Minerva System. Através desse serviço, a API poderá ser acessada, e as operações serão redirecionadas para outros serviços, de acordo com o domínio da regra de negócio em questão.
REST é o único módulo cujo Service possui um tipo diferente, sendo um tipo LoadBalancer, que fornece acesso direto à API através da porta 30000.
kubectl apply -f minerva-rest.yml
Utilitários de monitoramento
Com o deploy do sistema feito, poderemos também provisionar algumas ferramentas para ajudar no monitoramento do mesmo.
Prometheus
O Prometheus é um serviço que realiza scraping de informações expostas em endpoints de métricas. Através dele, é possível recuperar dados que podem ser posteriormente trabalhados para analisar a saúde de serviços ou até mesmo do cluster Kubernetes.
Configurando o k3s
Primeiramente, configure a sua instância do K3s, como orienta
esse link;
basta apenas, no seu nó master do cluster, criar o arquivo
/etc/rancher/k3s/config.yaml com o conteúdo:
etcd-expose-metrics: true
Em seguida, reinicie o serviço do K3s.
Instalando o Kube-State-Metrics
O serviço kube-state-metrics provê algumas métricas coletadas através dos serviços no cluster Kubernetes. Voce pôderá instalar uma configuração padrão, como colocado neste link, clonando o repositório do projeto e aplicando essa configuração:
git clone https://github.com/kubernetes/kube-state-metrics
kubectl apply -f kube-state-metrics/examples/standard/
Provisionando o Prometheus
Como o Prometheus realiza scraping de dados nos serviços do Kubernetes e até mesmo em outros serviços, ele necessita de configurações de RBAC, o que implica na criação de objetos como ClusterRoles, ClusterRoleBindings e ServiceAccounts. Além disso, o Prometheus possui arquivos de configuração em um ConfigMap, um Deployment e um Service.
kubectl apply -f util/prometheus.yml
Mongo Express
O Mongo Express é uma ferramenta para explorar e editar o conteúdo do
banco de dados não-relacional MongoDB. Esse serviço é exposto através de
um Service de tipo NodePort, na porta 31085.
O Mongo Express do Minerva já vem configurado com configuração de acesso
ao MongoDB. Caso sejam requisitadas credenciais para abrir o aplicativo,
utilize o usuário mongo e a senha mongo.
ATENÇÃO: Caso seja necessário usar uma ferramenta mais específica, como
MongoDB Compass, você poderá realizar port-forward do Deployment do MongoDB
e conectar-se à porta via localhost.
kubectl apply -f util/mongoexpress.yml
PgAdmin4
O PgAdmin4 é uma ferramenta para explorar e editar o conteúdo do banco de
dados relacional PostgreSQL. Esse serviço é exposto através de um Service
de tipo NodePort, na porta 31084.
O PgAdmin4 do Minerva já vem configurado com dados de acesso ao PostgreSQL.
Para efetuar login, use o usuário admin@admin.com e a senha admin.
Para acessar o PostgreSQL, você precisará do usuário e senha padrão do
mesmo também (postgres para ambos, por padrão).
ATENÇÃO: Caso seja necessário usar uma ferramenta mais específica, como
DBeaver, você poderá realizar port-forward do Deployment do PostgreSQL
e conectar-se à porta via localhost.
kubectl apply -f util/pgadmin.yml
Grafana
O Grafana é um serviço para criação e mostra de dashboards que operam a partir de métricas coletadas em serviços variados. No caso do Minerva, esses dados vêm principalmente do serviço Prometheus, previamente configurado.
Para o Grafana, provisionaremos alguns ConfigMaps com configuração inicial e alguns dashboards padrão para o cluster RabbitMQ. Como essa configuração inicial produz um arquivo relativamente grande, é necessário forçá-lo a ser processado de forma server-side.
As credenciais padrão do Grafana são o usuário admin e senha admin.
Durante o primeiro login, você poderá alterar a senha inicial.
kubectl apply -f --server-side=true util/grafana-data.yml
kubectl apply -f util/grafana.yml
Para mais detalhes da configuração do Grafana, veja a página de Ferramentas para monitoramento externo.
Ingresses (via Traefik)
Os Ingresses são formas mais explícitas de acesso a alguns serviços do cluster, pois abrem rotas propriamente ditas que "camuflam" requisições nas mesmas e realizam forwarding para serviços específicos.
Os Ingresses atualmente preparados são compatíveis com a infraestrutura padrão do K3s, que utiliza Traefik como proxy reverso de Ingresses padrão.
Atualmente, os ingresses exportam as seguintes rotas:
/api, para a API do Minerva System;/pgadmin, para o PgAdmin4;/mongoexpress, para o Mongo Express;/grafana, para o Grafana.
kubectl apply -f minerva-ingress.yml
Acessando serviços externamente
Pode ser necessário acessar, de forma externa, algum serviço que esteja no cluster, especialmente se o mesmo possuir um Service do tipo ClusterIP, que não permite acesso externo diretamente.
O Kubernetes provê algumas formas de realizar este acesso.
Acessando com Port Forward
Uma forma muito útil de acesso externo é o port forwarding, que realiza bind de uma porta da máquina local a uma porta específica de um pod específico. Também é possível referenciar um conjunto inteiro de réplicas através de um Deployment, ReplicaSet ou StatefulSet.
Para tanto, basta ter o kubectl instalado na sua máquina e
a configuração correta de acesso ao cluster.
O exemplo a seguir realiza port forwarding do MongoDB para
a máquina local, de forma que a porta 27017 do pod
esteja acessível localmente através da porta 9050. Esse
tipo de manobra será útil especialmente para acesso externo,
por exemplo, au usar o MongoDB Compass.
kubectl port-forward deployment/mongodb-deployment 9050:27017
Acesso via NodePort
Esse tipo de acesso envolve acessar alguns Services que possuam um tipo NodePort ou LoadBalancer, estando expostos sob uma porta em qualquer IP do cluster. A tabela a seguir mostra uma relação dessas portas.
| Serviço | Porta |
|---|---|
| API | 30000 |
| PgAdmin 4 | 31084 |
| Mongo Express | 31085 |
| Redis Commander | 31086 |
| Grafana | 31087 |
Monitoramento e testes
A seguir, estão listadas algumas configurações relacionadas a utilitários de monitoramento e testes do Minerva no cluster.
k9s
Uma das ferramentas possíveis de se utilizar para monitorar o cluster
é o k9s.
A ferramenta utiliza uma edição modal, muito parecida com o editor Vim. Os comandos possuem um sistema de autocompletar e são também mostrados na tela. Alguns comandos interessantes de serem utilizados são:
:q: Sair da aplicação.:po: Lista de Pods.:svc: Lista de Services.:dp: Lista de Deployments.:ing: Lista de Ingresses.:hpa: Lista de HorizontalPodAutoscalers.:pvc: Lista de PersistentVolumeClaims.:pv: Lista de PersistentVolumes.
Você poderá usar o k9s para visualizar logs e também para modificar
algumas propriedades mais avançadas também. É possível até mesmo acessar
diretamente o console dos contêineres.
kubernetes-el
O kubernetes-el é um pacote para o editor de texto Emacs que
permite inspecionar um cluster Kubernetes.
Para mais informações, veja o site oficial do pacote.
Dashboard do Kubernetes
É possível acessar o Dashboard padrão do Kubernetes para realizar gerenciamento e monitoramento, porém o K3s exige configuração extra.
Para ter acesso ao Dashboard, siga as orientações no site oficial da Rancher.
Testes de Stress
Há alguns testes de stress para o Minerva System. Estes testes servem principalmente para testar os limites e o comportamento do sistema quando o mesmo estiver sob uma grande carga de operações.
Testes de spike com K6
Os testes padrão são realizados através da ferramenta K6, porém essa ferramenta demanda a extensão Faker para que funcione adequadamente. Você poderá encontrar as instruções de instalação dessa extensão no repositório da mesma.
No diretório deploy/tests/k6, você poderá executar o k6 compilado com a extensão
referida. O host do cluster deverá ser informado através da variável de ambiente
MINERVA_HOST. Note que o k6 assume que o host informado possua uma rota /api,
então você deverá garantir que o Ingress do cluster esteja funcionando.
O exemplo a seguir mostra como executar os spike tests para stress de operações de sessão e de usuários.
# Testes de sessão
MINERVA_HOST=http://$IP_DO_CLUSTER k6 run session_spike.js
# Testes de usuários
MINERVA_HOST=http://$IP_DO_CLUSTER k6 run users_spike.js
A execução dos testes gerará um arquivo html ao final, que mostra um formato
interativo para inspeção dos resultados de testes.
Testes de stress legados (via Bash)
Para realizar testes de stress com o formato legado, use o script
deploy/tests/legacy/stress_test.sh.
Você poderá testar cada sistema crucial usando um comando como este:
./deploy/tests/legacy/stress_test.sh $IP_DO_CLUSTER/api user
Para maiores informações, execute o script sem argumentos e veja instruções rápidas de utilização.
Ferramentas para monitoramento externo
Esta seção demonstra algumas ferramentas que podem ser utilizadas para monitoramento dos serviços cujo deploy tenha sido realizado por meio de Kubernetes.
A maioria dos serviços a seguir pode ser acessado através de port-forward.
Swagger e RapiDoc
A API do Minerva System possui uma especificação compliant com OpenAPI 3, sendo portanto
testável a partir de vários serviços. A especificação OAS do Minerva System é sempre
exportada através do arquivo openapi.json, pela própria API (acessível na raiz do
subpath no qual a mesma é provisionada; no caso do k8s, como a API opera em /api,
esse arquivo pode ser encontrado em /api/openapi.json).
Como forma padrão para testar requisições, a API do Minerva System provisiona também
duas interfaces: Swagger e RapiDoc. Ambas são construídas pela API em si e
não são criadas de forma externa à mesma. Além disso, ambas estarão acessíveis mesmo
ao executar o Gateway da aplicação (microsserviço minerva-rest) localmente.
Usando o Swagger
O Swagger é a interface gráfica mais utilizada atualmente para testar uma API pública.
Para acessá-la, abra seu navegador de internet e acesse a página pela rota /api/swagger.
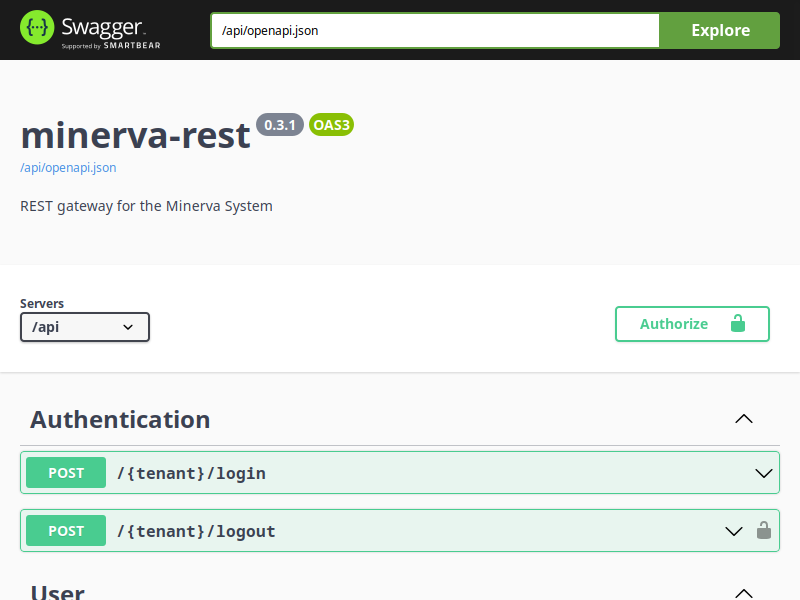
Após utilizar a requisição de login, você poderá clicar no botão Authorize e, na tela a seguir, colar o token de autenticação.
Após clicar no botão Authorize da tela acima, requisições subsequentes serão realizadas com um Bearer Token incluído no cabeçalho das mesmas.
Usando o RapiDoc
O RapiDoc é uma interface alternativa ao Swagger, sendo mais compacta e com algumas
funcionalidades diferentes. Para acessá-la, abra seu navegador de internet e acesse a
página pela rota /api/rapidoc.
De forma similar ao Swagger, após utilizar a requisição de login, você poderá colar
o token de autenticação na caixa de texto api-token da seção AUTHENTICATION, e clicar
no botão SET. Requisições subsequentes serão realizadas com um Bearer Token incluído
no cabeçalho das mesmas.
Grafana
A ferramenta Grafana é uma ferramenta de criação de dashboards para monitoramento. O Minerva System provisiona o Grafana pelo Kubernetes, e o alimenta com dados primariamente através do serviço Prometheus.
O Grafana não exige configuração extra para ser acessado, basta acessar o cluster
através de um navegador, na rota /grafana, já que existe um Ingress exclusivo
para este serviço. Ao realizar login, você poderá entrar na conta do administrador
através do usuário padrão admin e senha inicial admin; após o login, você
também poderá mudar a senha do admin, se quiser.
Ao acessar o Grafana, você será agraciado com uma tela inicial.
É possível, por fim, acessar alguns dashboards já provisionados através da configuração padrão do Minerva System, ou instalar algum outro dashboard, desde que este seja capaz de trabalhar com as métricas fornecidas por padrão.
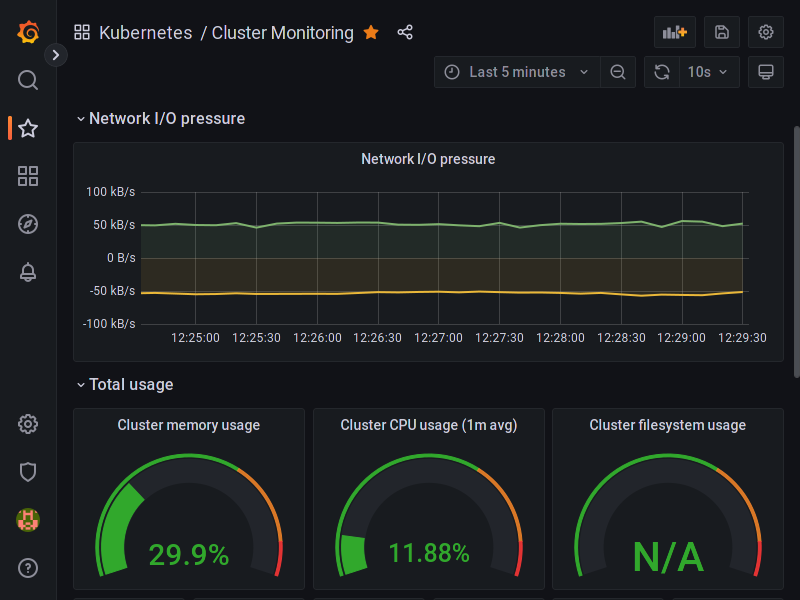
Por padrão, o Prometheus fornece para o Grafana métricas de:
- Cluster (Kubernetes);
- RabbitMQ.
Alguns dashboards úteis
Os dashboards a seguir são úteis para monitoramento do cluster Kubernetes através dos dados obtidos pelo Prometheus através do scraping das várias rotas de métricas do K8s, e podem ser importados diretamente pelo Grafana.
- Kubernetes Cluster Monitoring (via Prometheus)
- Kubernetes apiserver
- 1 K8S for Prometheus Dashboard 20211010 EN
MongoDB Compass (para MongoDB)
O MongoDB Compass é uma ferramenta para desktop que permite inspecionar documentos no MongoDB.
Para utilizá-lo, primeiramente realize port-forward do MongoDB para sua porta padrão na máquina atual:
kubectl port-forward -n minerva deployment/mongodb-deployment 27017:27017
Em seguida, conecte-se à instância do MongoDB através do host localhost:27017,
com usuários e senha padrão root e mongo.
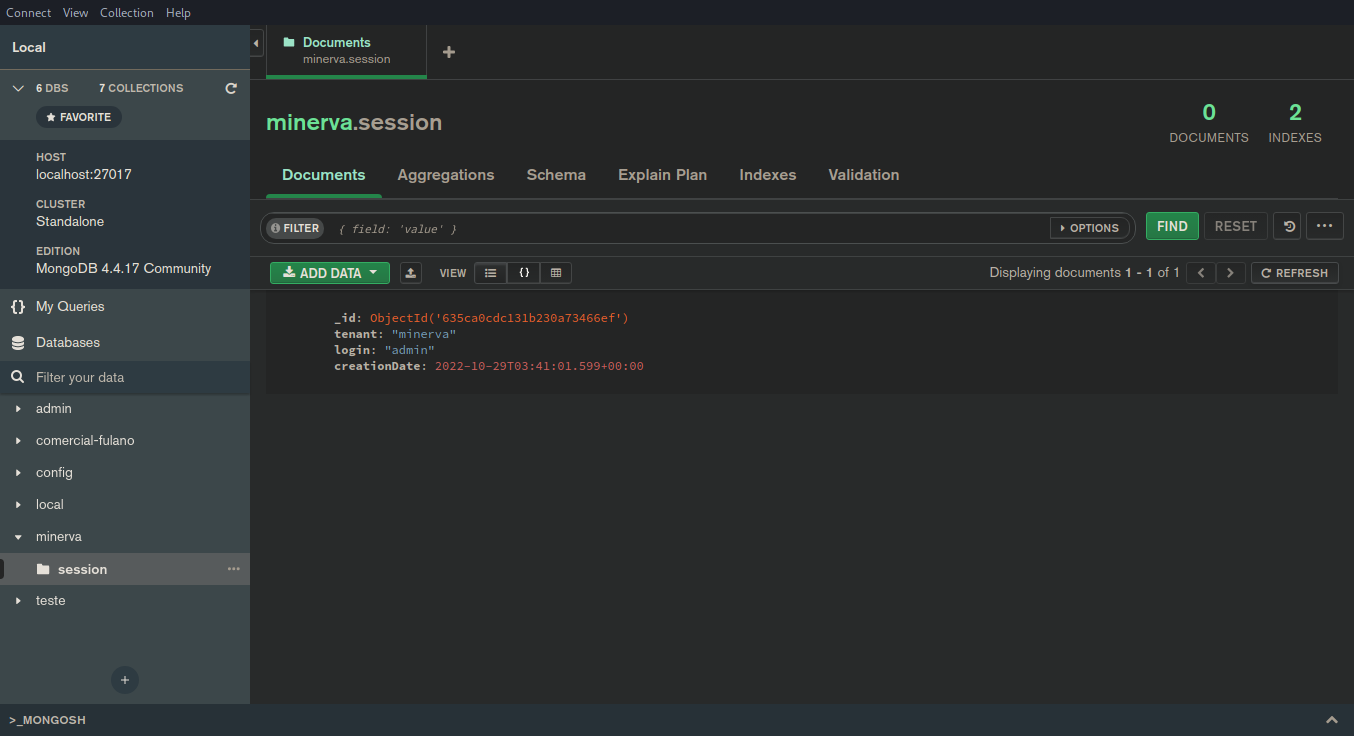
RESP.app (para Redis)
O RESP.app é uma ferramenta para desktop que permite inspecionar dados em cache em um serviço Redis ou Redis Cluster.
Para acessar o Redis através dele, realize primeiro o port-forward para a porta padrão do Redis na sua máquina:
kubectl port-forward -n minerva statefulset/redis 6379:6379
Em seguida, clique em Connect To Redis Server. No campo de URL, digite o mesmo
texto do hint apresentado (redis://localhost:6379), e então clique em Import.
Na próxima janela, dê um nome para a conexão e clique em OK. Não é necessário segurança ou autenticação.
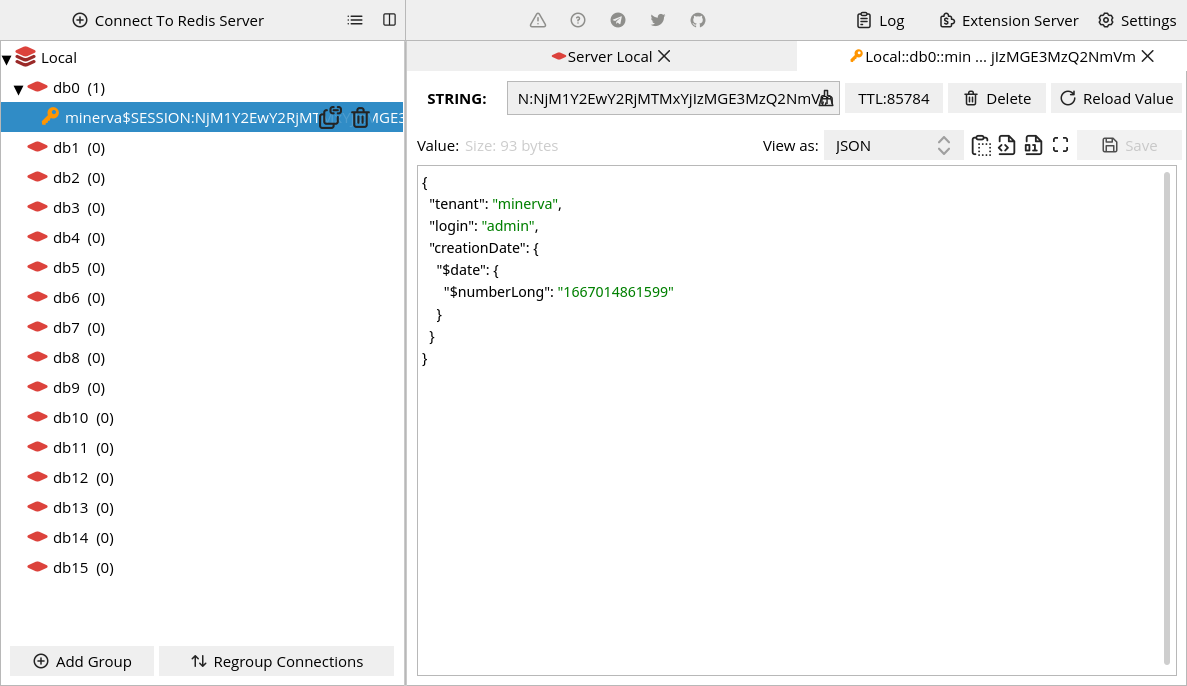
DBeaver Community Edition (para PostgreSQL)
O DBeaver é um cliente universal para banco de dados que permite inspecionar tabelas, schemas, e executar código SQL.
Para acessar o banco de dados PostgreSQL através dele, primeiramente exponha o banco do cluster localmente através de port-forward na porta padrão esperada:
kubectl port-forward -n minerva deployment/postgresql-deployment 5432:5432
Em seguida, abra o DBeaver e clique na opção para uma nova conexão, no menu Banco de dados (ou Database). Selecione a opção PostgreSQL, clique em Next, e instale quaisquer drivers necessários que venham a ser pedidos.
Em seguida, você poderá manter o host e porta padrões (localhost:5432), mas
deverá alterar o campo Database de acordo com o tenant que você deseja acessar.
Além disso, por padrão, use usuário postgres e senha postgres.
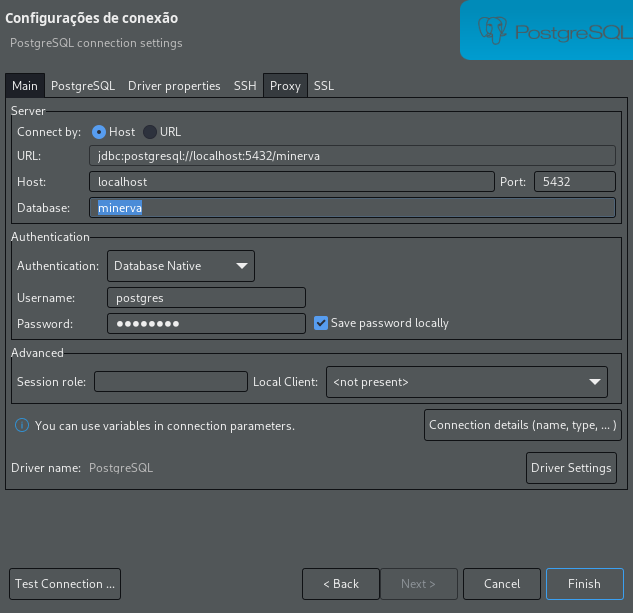
Você poderá agora navegar nas abas à esquerda para localizar quaisquer tabalas que desejar, e poderá também fazer outras operações com o banco.
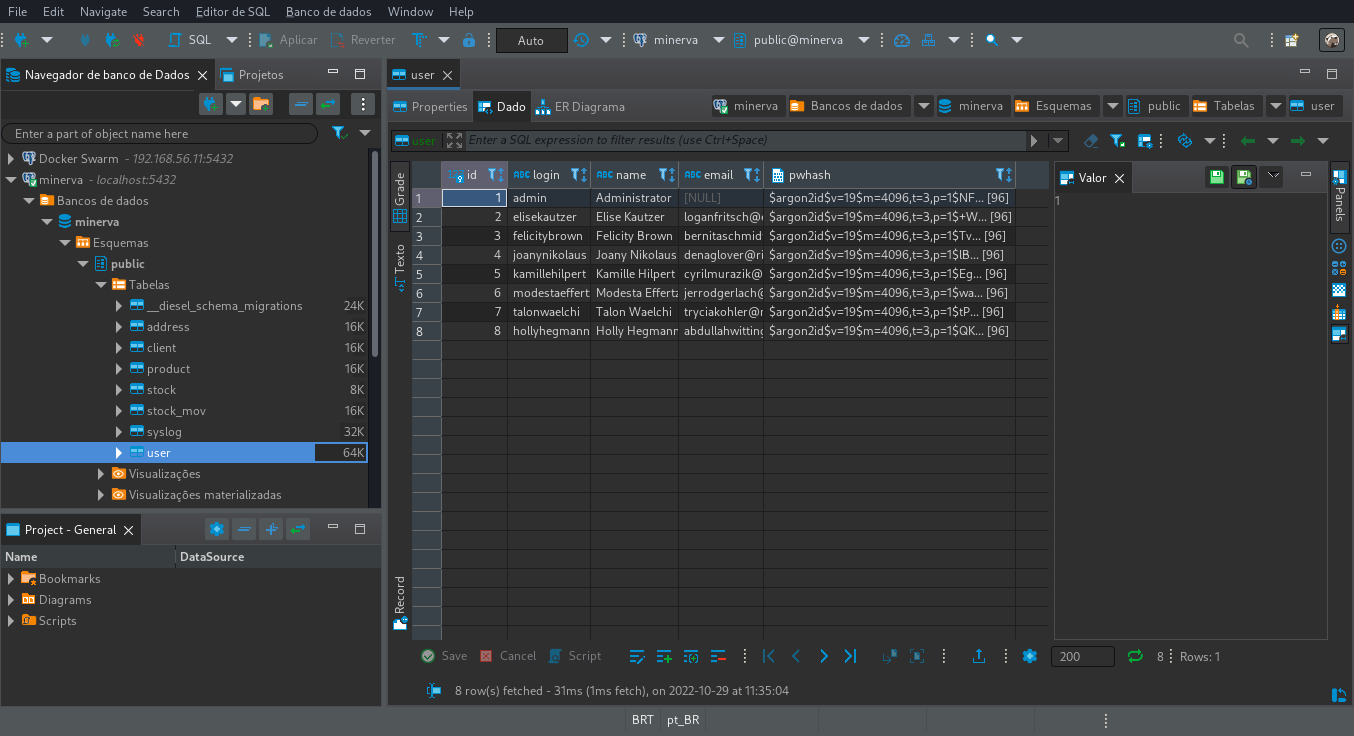
RabbitMQ
O serviço de mensageria RabbitMQ já provê um painel de monitoramento e configuração em seu deployment. Esse painel não fica normalmente exposto pelo Minerva System, mas pode ser acessado através de port-forward.
O RabbitMQ expõe três portas:
5672(portaamqp, para conexões com filas);15672(portamanagement, para gerenciamento da aplicação);15692(portavhost, para gerenciamento de hosts virtuais, em especial usado para multi-tenant).
Para acessar o painel do RabbitMQ, vamos expor localmente, através de port-forward,
a porta management (15672). Mas caso seja necessário realizar alguma operação
extra, você poderá expor as portas anteriores também.
kubectl port-forward -n minerva deployment/rabbitmq-deployment 15672:15672
Em seguida, acesse o painel do RabbitMQ pelo navegador, em http://localhost:15672.
Para realizar login, use o usuário padrão rabbitmq e a senha minerva.
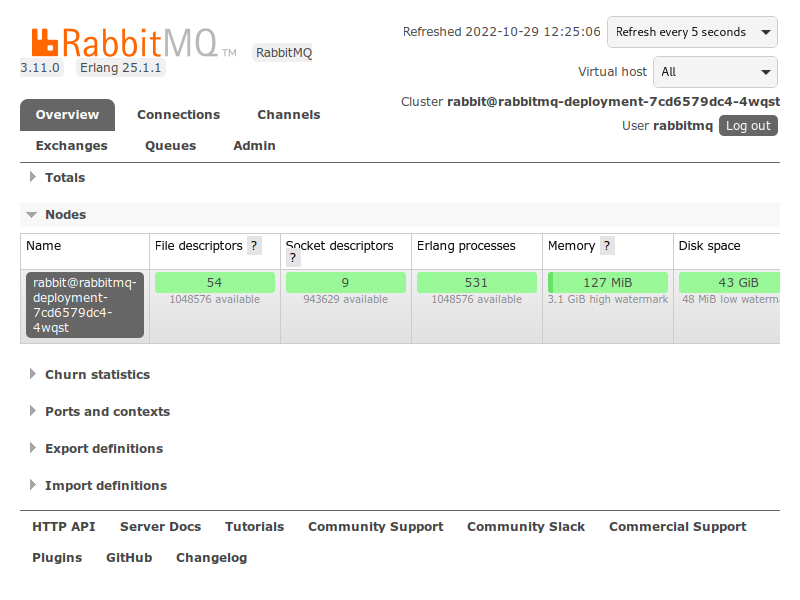
ElasticSearch
A ferramenta ElasticSearch é uma ferramenta de busca e analytics através de documentos que podem se interrelacionar, como por exemplo, no caso de logs. O Minerva System provisiona o ElasticSearch pelo Kubernetes para indexação e armazenamento de logs. Tais dados são alimentados primariamente através do serviço Fluentd, que realiza scraping dos logs de cada pod.
Para realizar queries e analisar os dados armazenados no ElasticSearch, o Minerva System também provisiona o Kibana, uma interface gráfica própria que se integra com o ElasticSearch.
O Kibana não exige configuração extra e nem mesmo autenticação para ser acessado
(note que isso poderá mudar no futuro). Para tanto, você poderá utilizar o
Ingress exclusivo para o Kibana, que poderá ser acessado na rota /kibana do
cluster.
Ao acessar o Kibana, você verá a seguinte tela inicial.
Em seguida, no menu lateral, vá até a sessão Analytics e selecione Discover.
Você verá a tela de gerenciamento e logs. Para adicionar os logs do cluster (enviados ao ElasticSearch via Fluentd através de log stashes), clique no botão de data views (canto superior esquerdo) e selecione a opção Create a data view, como mostra a seguir.
Na janela que abre, dê o nome que quiser ao data view, e no campo Index pattern,
escreva logstash-*, para indicar que você deseja consumir dados de todos os
log stashes criados pelo Fluentd.
Após clicar em "Save data view to Kibana", você poderá realizar queries diretamente no data view informado. A tela a seguir exemplifica uma query para exibir logs dos microsserviços.
Você poderá também adicionar novos campos à tabela, selecionando campos possíveis no menu de filtros que fica à esquerda.
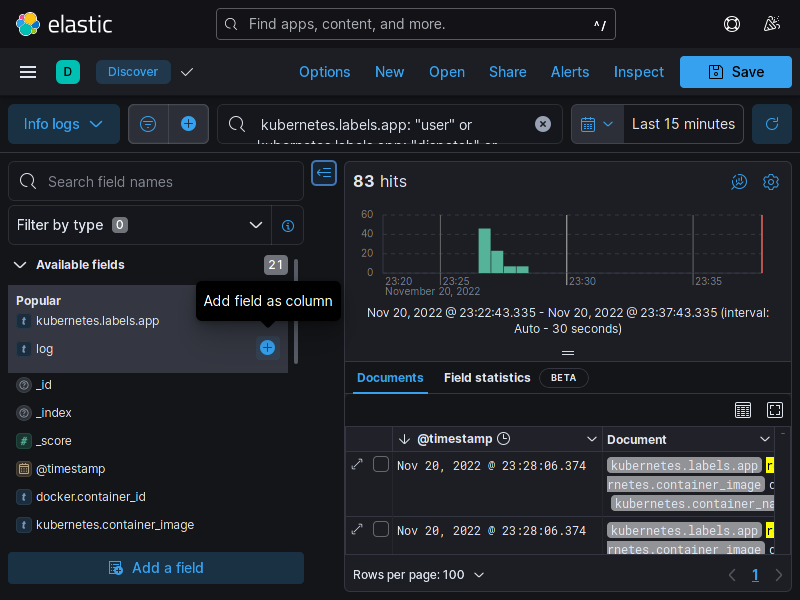
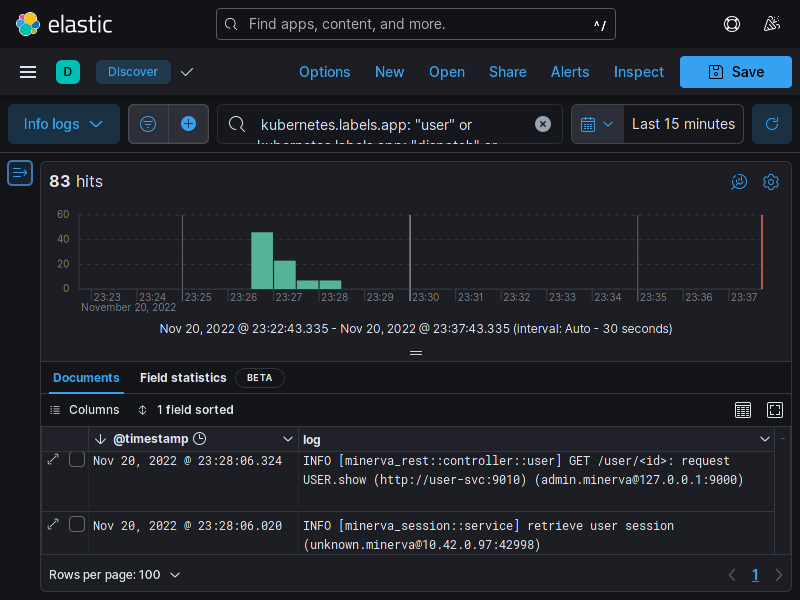
Diagramas de arquitetura do cluster
Esta seção contém diagramas relacionados à arquitetura do Minerva System, quando realizado o seu deploy através do uso de Kubernetes.
Nesta página, você poderá observar a arquitetura do sistema de forma geral. As próximas subseções mostram diagramas específicos demonstrando o deployment de cada um dos componentes necessários no Kubernetes.
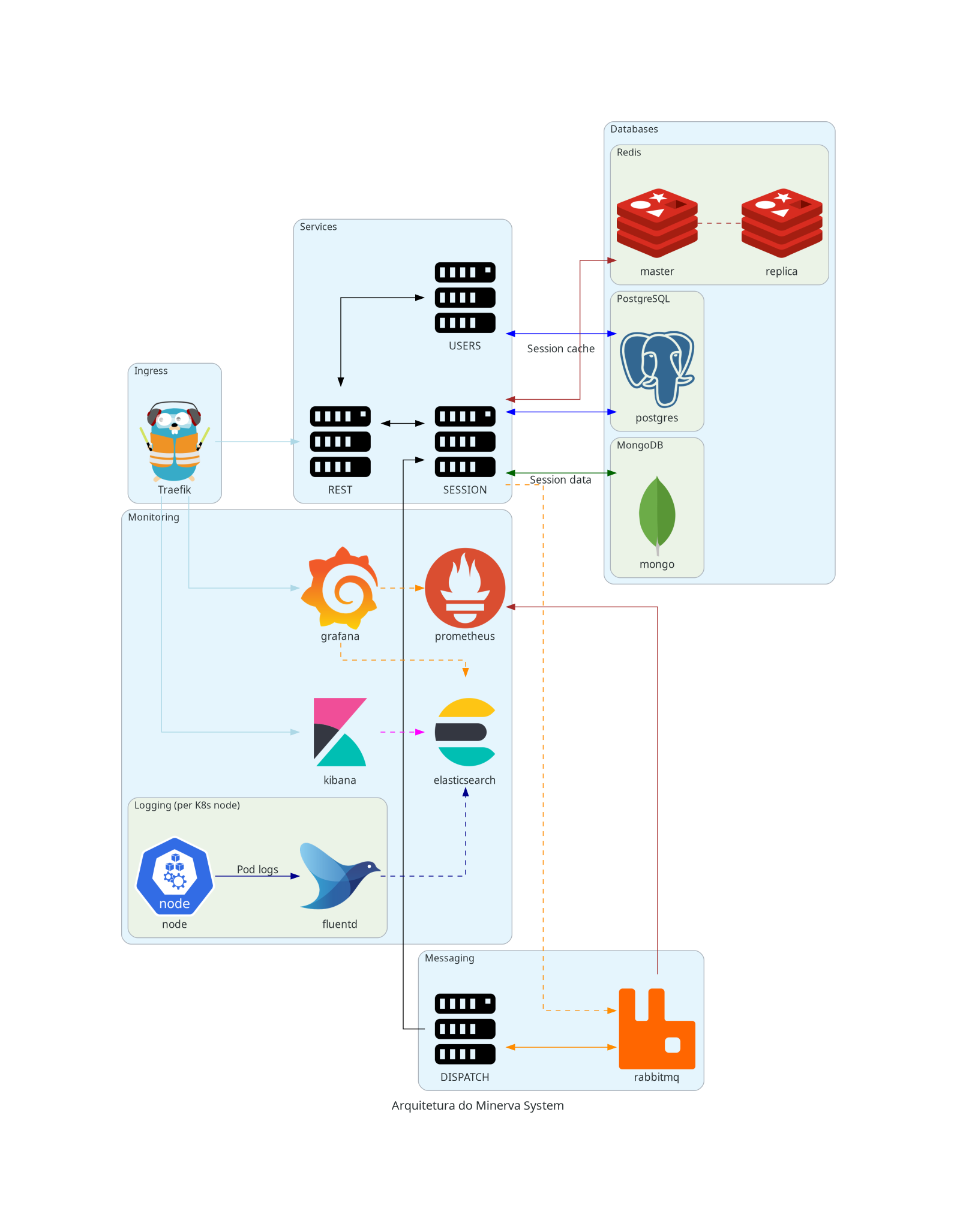
Serviço REST
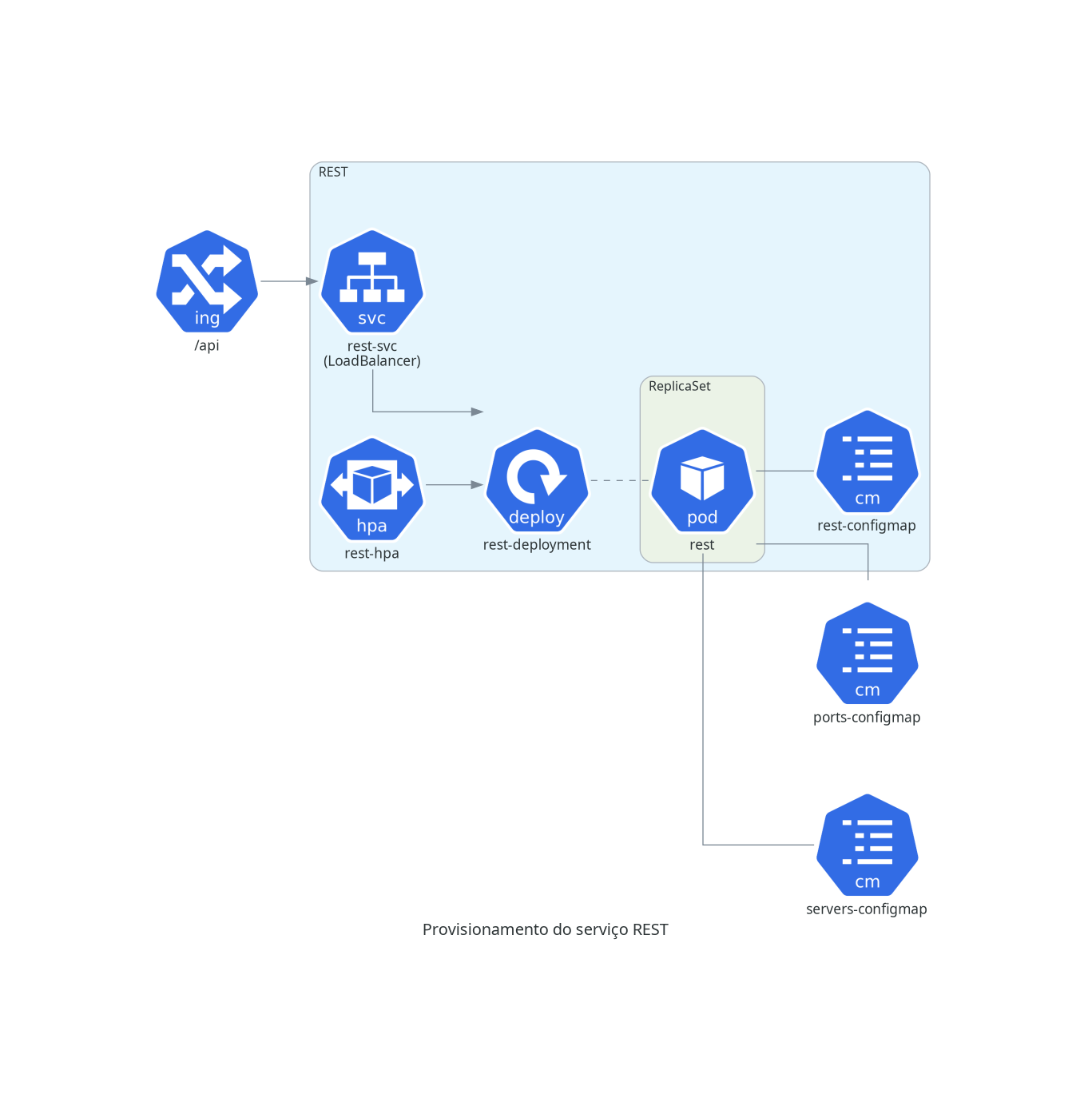
Serviço SESSION
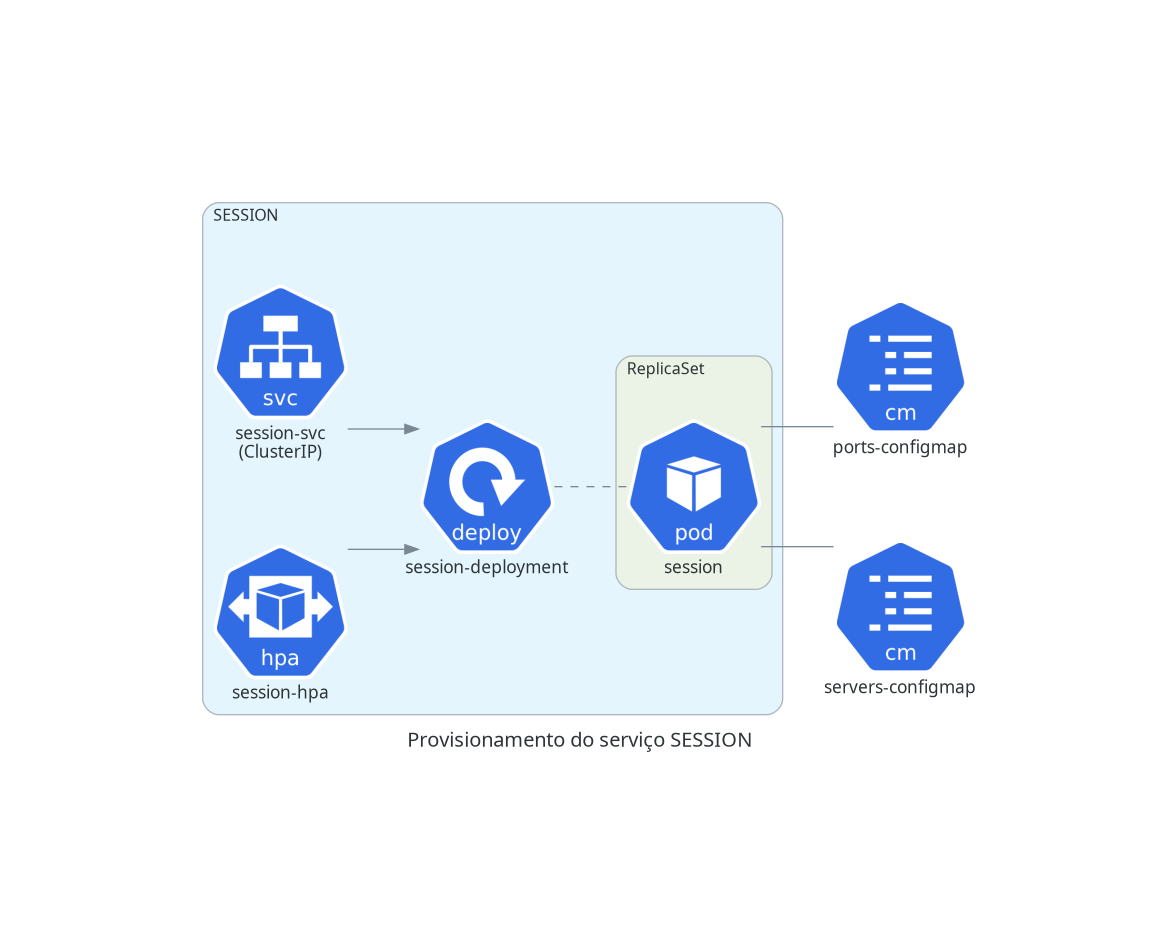
Serviço USER
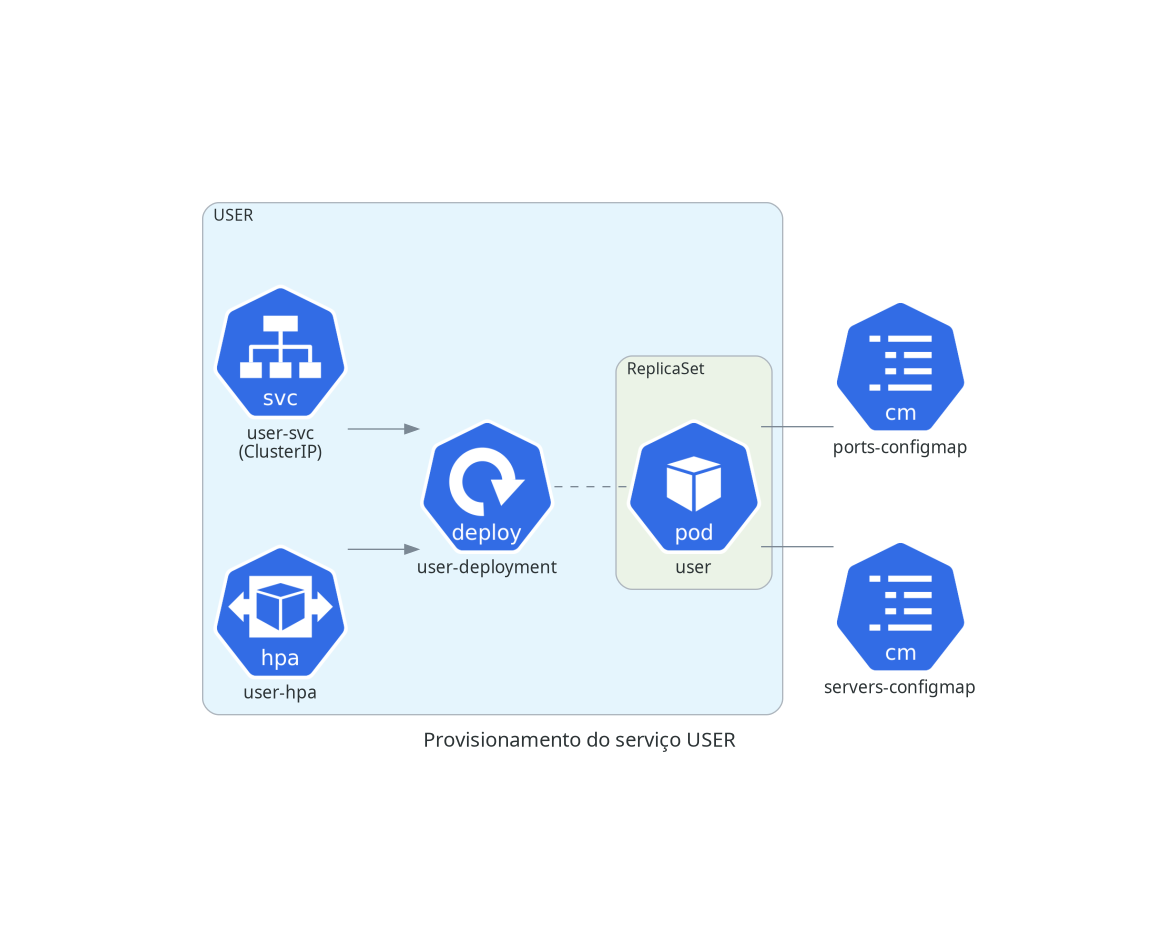
Serviço DISPATCH
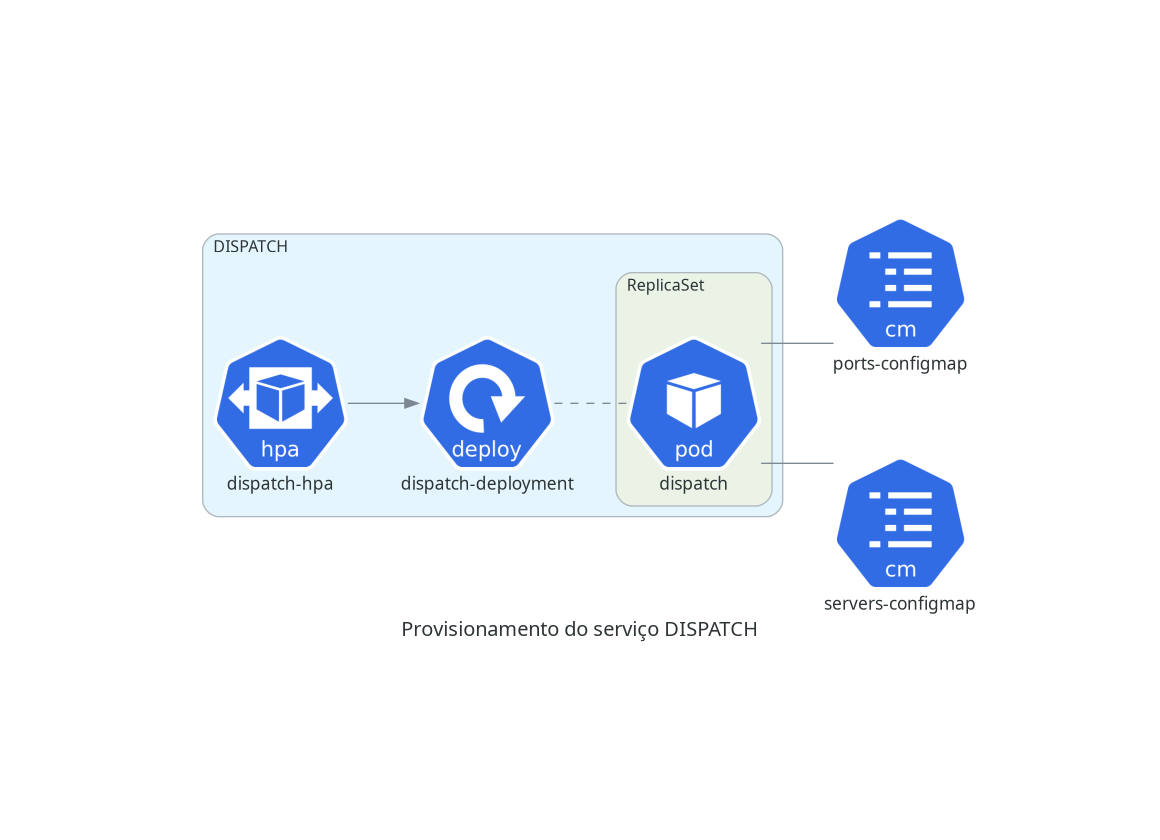
Serviço PostgreSQL
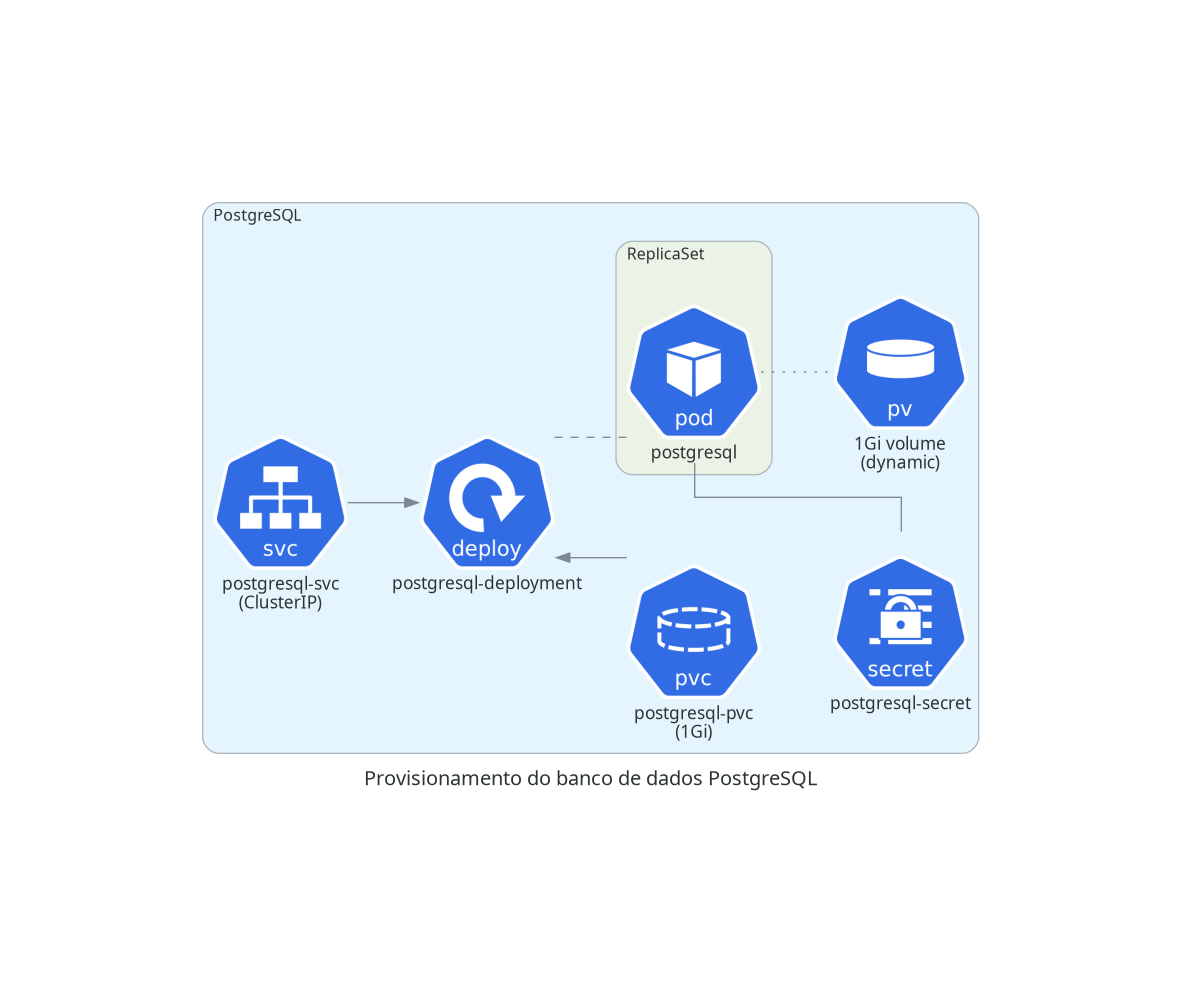
Serviço MongoDB
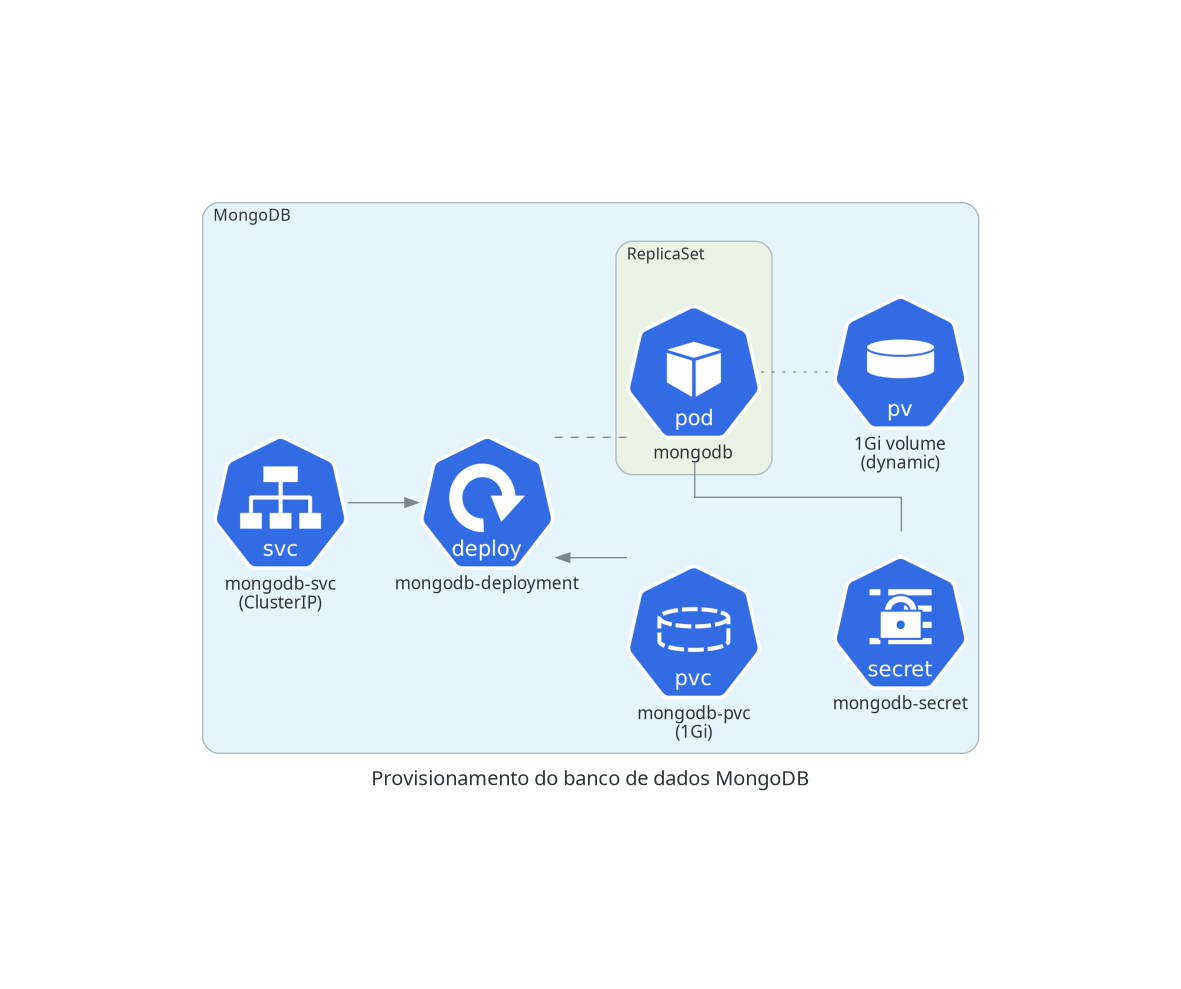
Serviço Redis
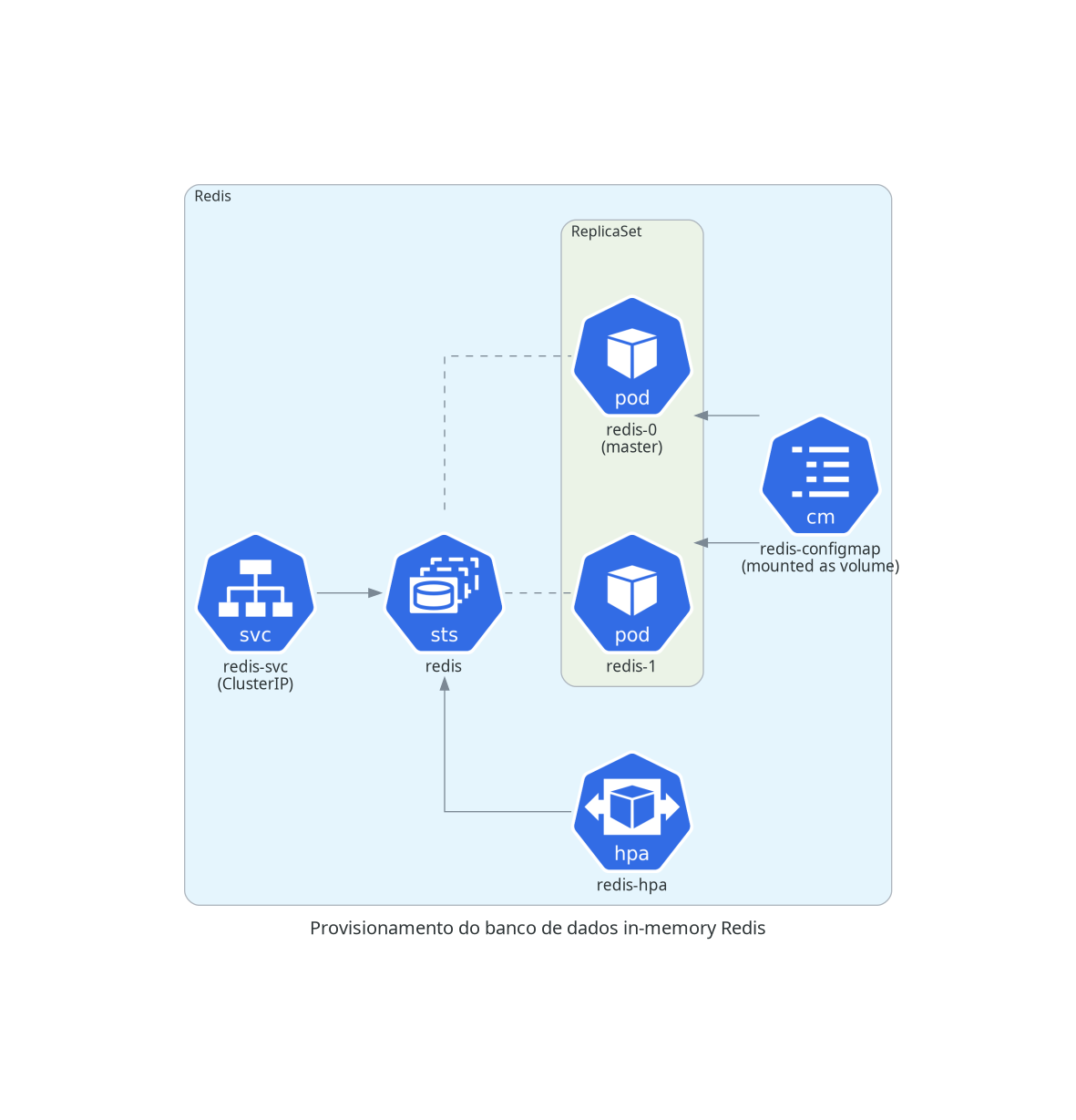
Serviço RabbitMQ
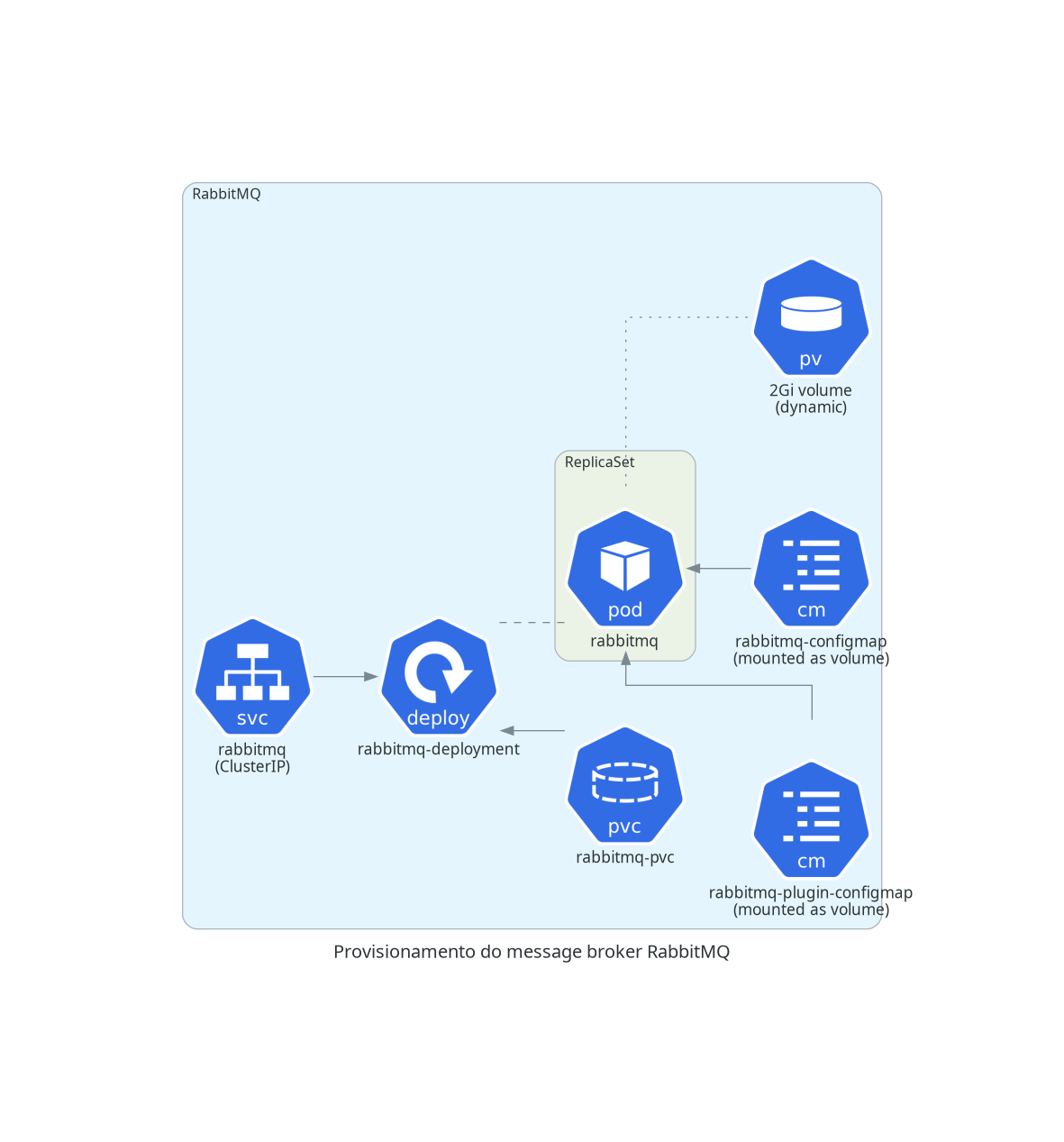
Serviço Prometheus
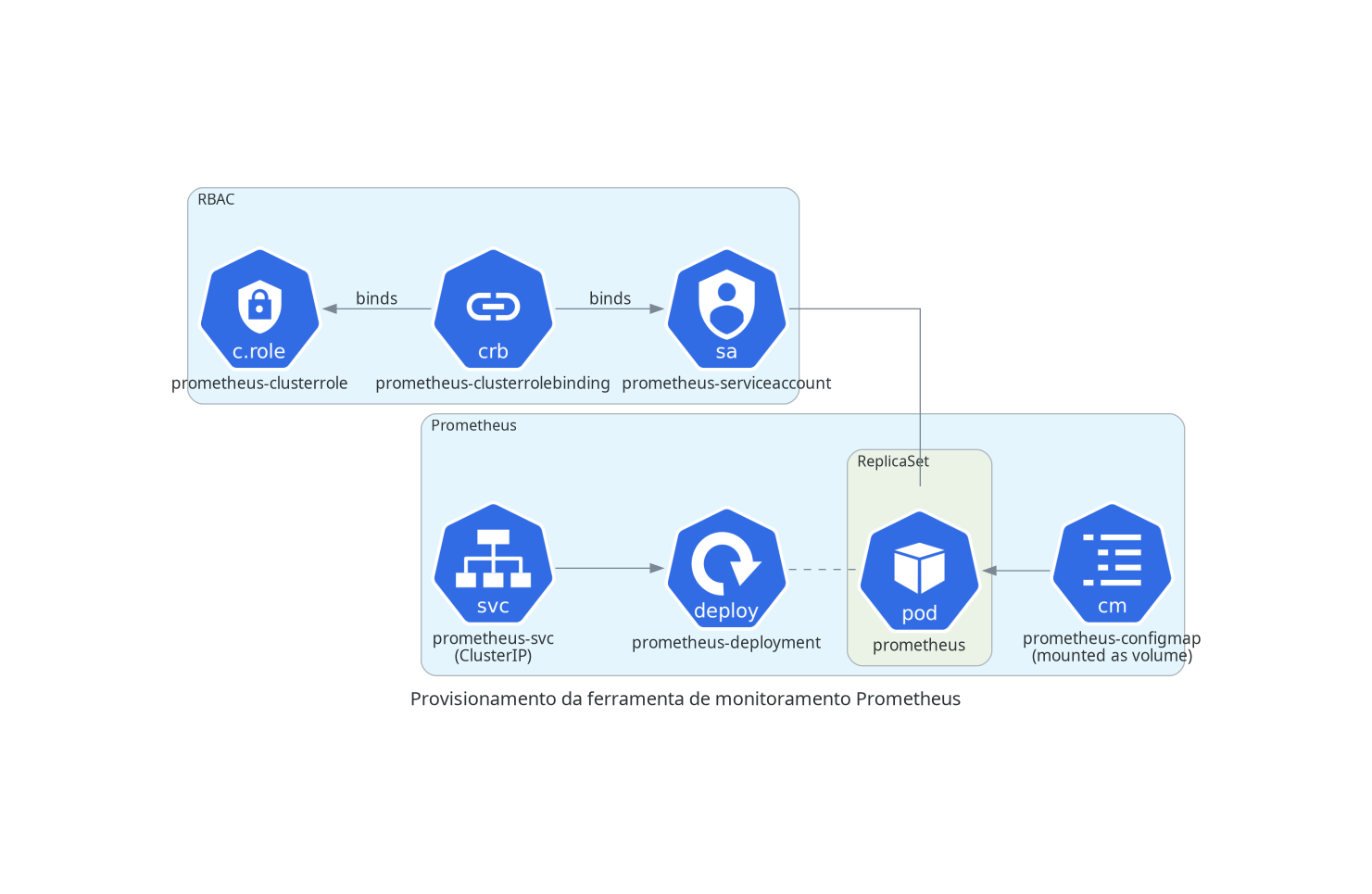
Serviço Fluentd
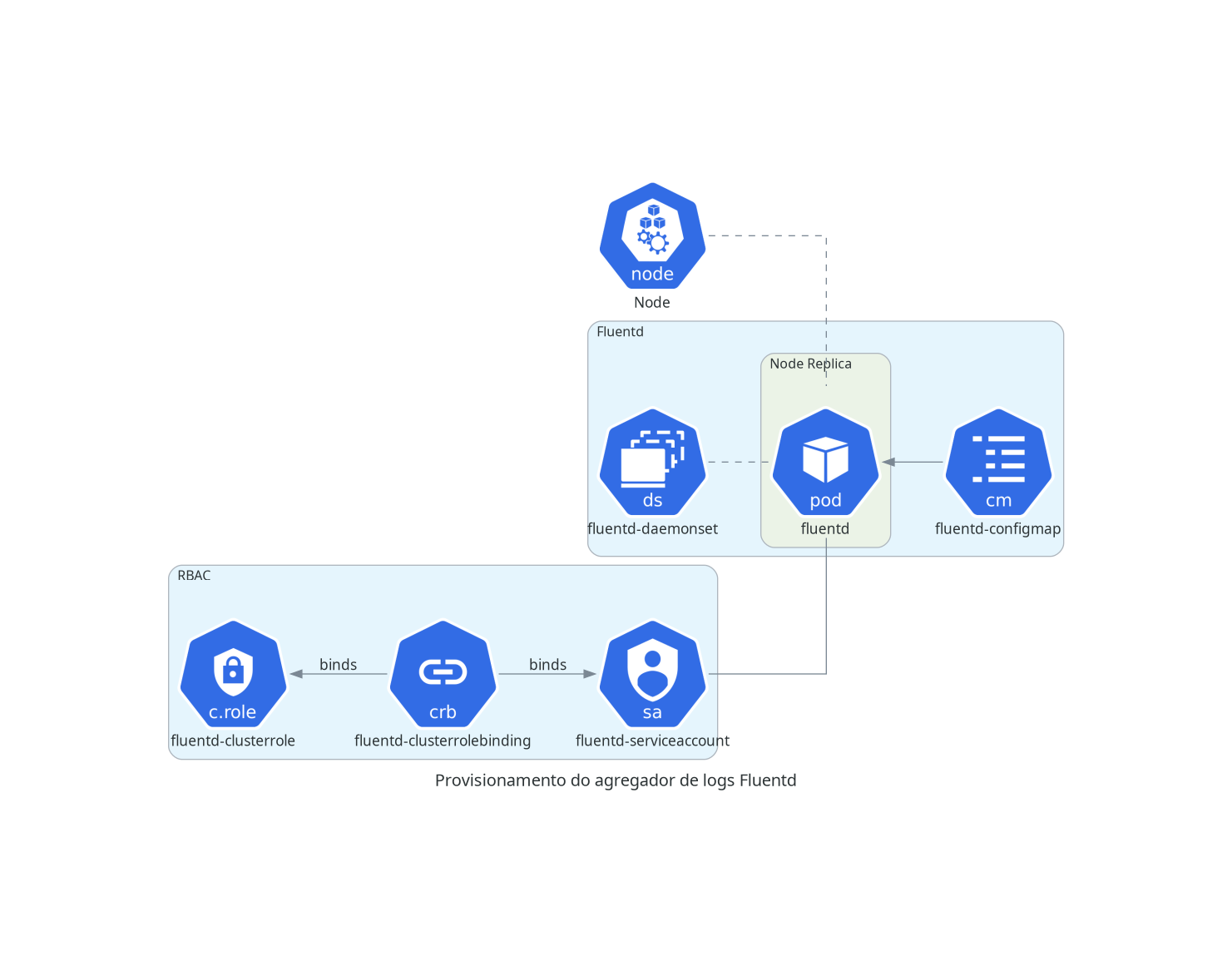
Serviço Elasticsearch
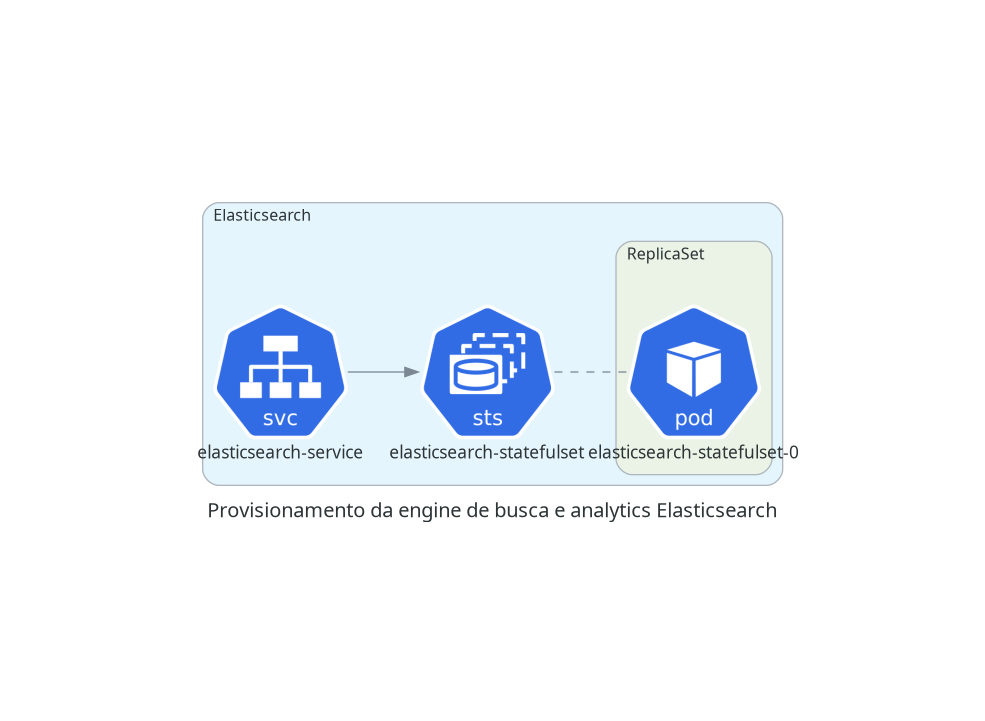
Serviço Grafana
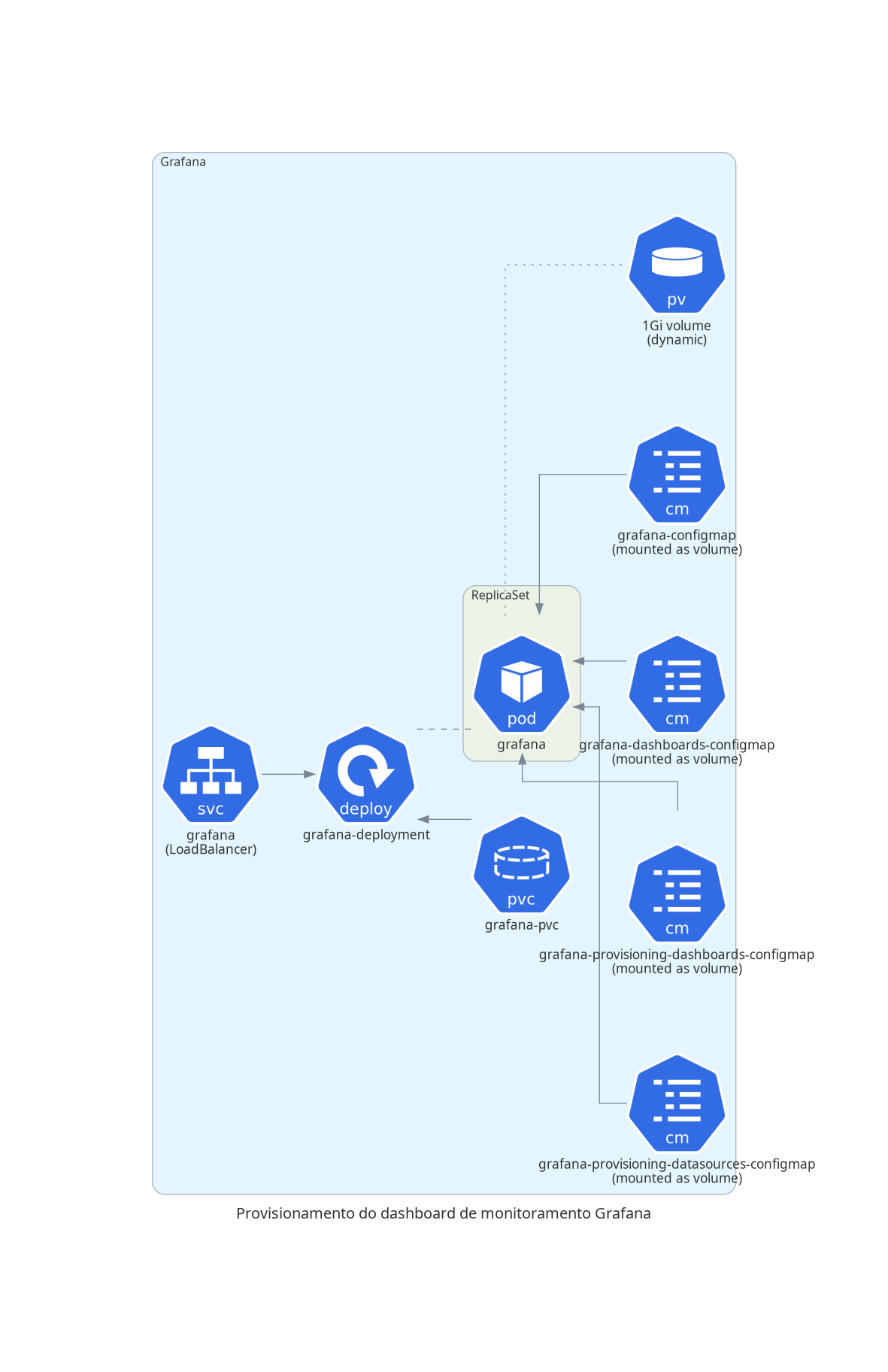
Serviço Kibana
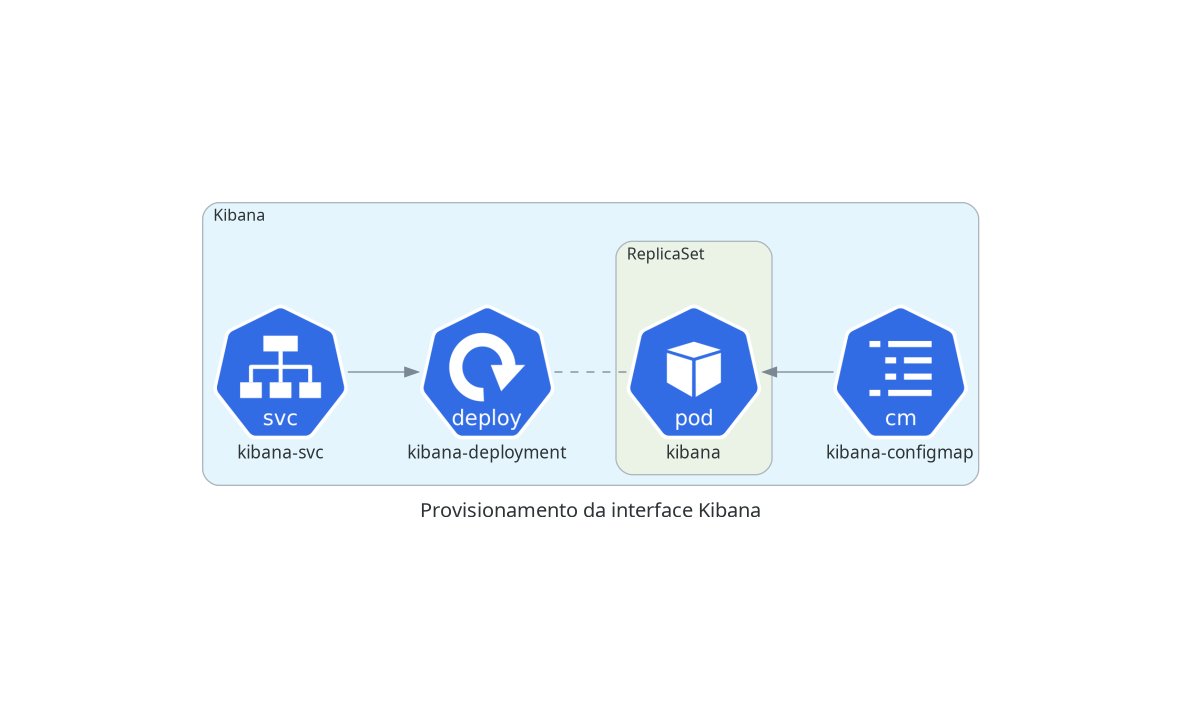
Testes
As seções a seguir descrevem ferramentas e práticas relacionadas a testes na aplicação. Estes testes podem estar relacionados a testes unitários, testes de integração e testes de carga e stress.
Testes unitários
Objetivo
Os testes unitários são criados de acordo com a entrega de cada demanda da aplicação. Eles devem ser feitos para testar unidades do projeto que venham a ser suficientemente pequenas para tal.
Execução
Os testes unitários são executados juntamente com os de integração ao usar
o comando cargo test na raiz do projeto.
Testes de integração
Objetivo
Os testes de integração são criados de forma mais rara, por exigirem um pouco mais de esforço de implementação, pois geralmente demandam que um ou mais serviço esteja em execução para que a integração entre as partes do sistema seja testada.
Atualmente, apenas o módulo minerva-rest possui testes de integração. Estes
testes geralmente iniciam outros microsserviços com os quais a aplicação se
comunica.
Um padrão comum no Minerva System é garantir que os testes de integração sejam executados sequencialmente, e não paralelamente, para evitar concorrência entre os módulos.
Execução
Os testes de integração são executados juntamente com os unitários ao usar
o comando cargo test na raiz do projeto.
Testes de Carga

A aplicação possui também testes de carga para avaliar como o sistema age sob um grande volume de acessos e operações. Para isso, usamos a ferramenta Grafana k6.
Requisitos
Para executar os testes, você precisará do k6 instalado e também do Node v16.19.1.
Preparando os testes
Os testes encontram-se no diretório deploy/tests/k6/load-test. Navegue
até o mesmo, e então instale as dependências:
npm install
Em seguida, você poderá, opcionalmente, definir algumas variáveis de ambiente para que o teste funcione, de acordo com a tabela a seguir:
| Variável | Descrição | Valor Padrão |
|---|---|---|
MINERVA_HOST | Host da API do Minerva | http://localhost:9000/api |
MINERVA_TENANT | Inquilino a ser usado para testes | teste |
Executando os testes
Em seguida, execute os testes usado o comando:
npm run test